

画像の文字をOCR技術で出力する。
OCR(Optical Character Recognition)、日本語で「光学文字認識」と呼ばれる技術は、手書きの文字や印刷された書類の活字をスキャナーやカメラなどで画像化し、その画像の文字を認識して、テキストのデジタルデータへと変換する技術のことをいいます。
ビジネスや日常生活でデジタル化が進む現代で、書類や書籍など印刷されたアナログ情報をデータ化するニーズが高まっていて、OCRの需要が今後さらに拡大していきます。
本記事では、Pythonを使って、画像の文字を認識する方法を紹介します。
- Pythonを使う人
- OCRに興味がある人
- Tesseractのインストールをしたい人
- Pythonで画像から文字認識をしたい人
- 業務を効率化したい人
Tesseract

Tesseractは、ヒューレット・パッカード(HP)が開発を進め、Googleが後援している光学式文字認識エンジンです。
Windows、Linux、macOSなどのオペレーティングシステムで利用できます。
Tesseractは、多数の言語に対応しており、日本語も使用可能なOCR機能です。
Tesseractのインストール(windowsの場合)
Tesseractはコマンドプロンプトでインストールするのではなく、外部からexeファイルをインストールする必要があります。
「Tesseract at UB Mannheim-GitHub」にアクセスをして、
最新版のパッケージをインストールしてください。
ダウンロードしたインストーラーの指示に従い、インストールをします。
※画像は、ライセンスの確認です。
「Next」・「I agree」を進めていき、「Choose Components」までたどり着いたら、
ここから操作が必要です。
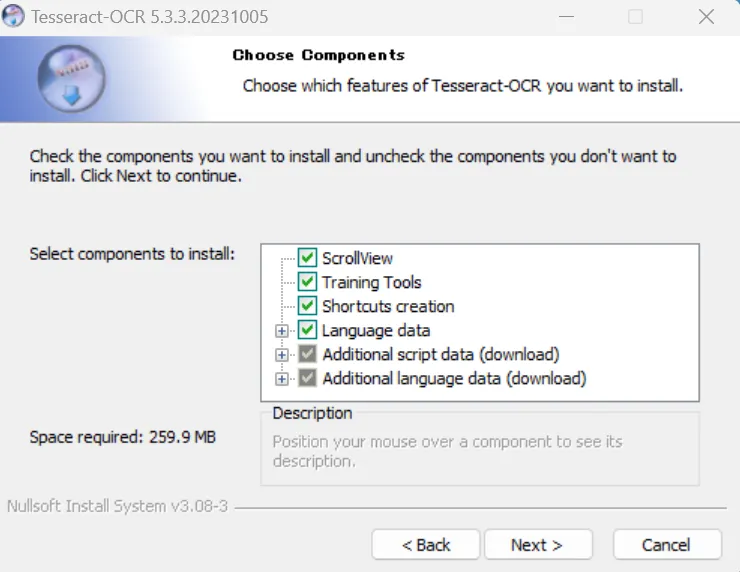
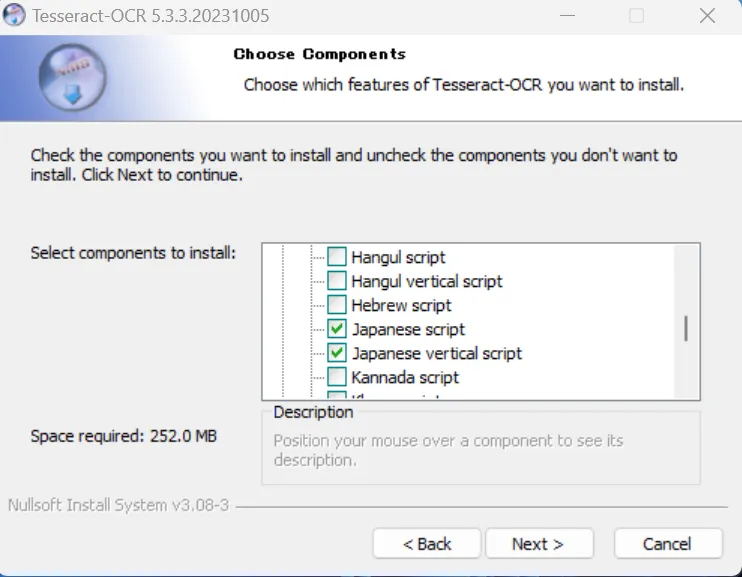
「Additional script data (download)」の「+」を押して展開してください。
項目の中から日本語(Japanese~)にチェックを入れてください。
これにより、tesseractのocr機能で日本語も文字認識できるようになります。
同様に「Additional language data (download)」項目の中から、日本語(Japanese~)にチェックを入れてください。
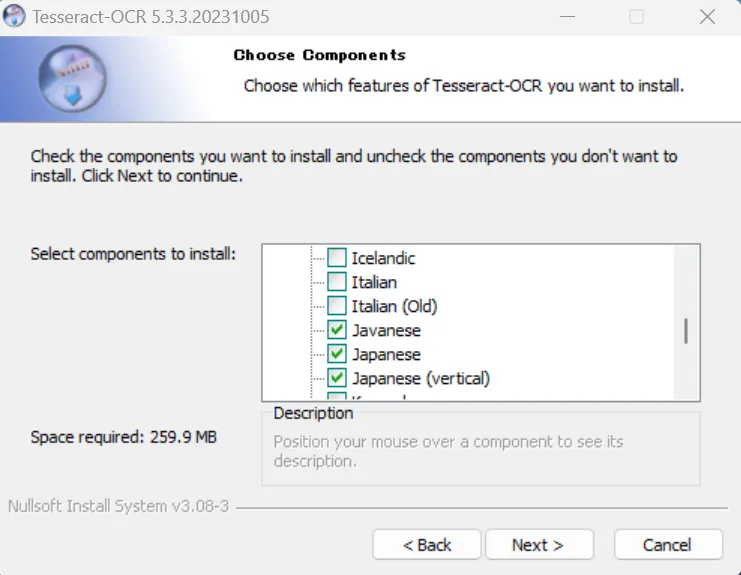
これらが完了したら、次に進み、インストールを完了させてください。
MacでTesseractをインストール
macの場合は、Homebrewを使用してTesseractをインストールすることができます。
brew install tesseractWindowsでは、exeファイルをインストールしなければいけませんでしたが、Macの場合は、たったのこれだけです。
クリエイターのMac離れを言われていますが、OCRは、Macの方が手際よくできそうです。

Tesseractは商用利用可能か
Tesseract OCR は、Apache License 2.0 の下で公開されているオープンソースであるため、商用利用が可能です。
Apache License 2.0は、ソフトウェアを自由に使用、改変、配布することが許可されており、商用利用も含まれます。
しかし商用利用可能でも、著作権は開発者に属するので、節度が必要です。
ビジネスで使用する際は、必ずライセンスを一読し詳細をご確認ください。
C#のOCRでもTesseractが有効
Pythonだけではなく、C#でもOCR機能が使うことができます。C#はWindowsのデスクトップアプリを作成するときに使う言語であるためC#とOCR機能はとても相性が良いです。
Tesseractを開発PCにインストールしてあれば、Visual StudioでNuGetパッケージをインストールすることでC#のOCR機能が導入できます。
PyOCR

Tesseractをインストールしたので使用しているPCで、紙に印刷された文字をPCに起こすことができるようになりました。
次に、PythonでOCRを起動させるようにPyOCRを使えるようにします。
TesseractはPython専用ではないため、Pythonコードで動作させるパッケージが必要になります。
PyOCRは、OCRエンジンと統合するPythonラッパーライブラリであり、先ほどインストールしたTesseractをはじめ一般的なOCRエンジンと連携できます。
連携によってPyOCRを使用してさまざまなテキスト認識プロジェクトを実行できます。
PyOCRを使用するためには、OCRエンジンをインストールし、Pythonコードを使用して統合したOCRタスクを実行できます。
PyOCRはPillowのサポートによって、jpeg, png, gif, bmpなど様々な画像形式に対応しています。

Pythonでは、画像の形式(拡張子)を変更することができます。
PyOCRのインストール
ターミナルまたはコマンドプロンプトを開き、
以下のコマンドを実行してPyOCRをインストールします。
pip install pyocrPyOCRは商用利用可能か
PyOCRは、オープンソースのOCR(Optical Character Recognition)ライブラリで、Apache License 2.0のもとで提供されています。
ゆえに、商用利用も含めて許可されていますが、いくつかの条件があります。
- 著作権表示の維持: ソースコードや関連するドキュメントに元の著作権表示やライセンス通知を残す必要があります。
- 責任免除: ライセンス提供者は、使用に伴う責任を負いません。ソフトウェアは「現状のまま」提供されます。
- 同じライセンスの維持: 変更したコードを再配布する場合、同じApache License 2.0で提供するか、互換性のあるライセンスを使用する必要があります。
詳細は、公式サイトで各自確認してください。
Pythonで画像の文字を表示する

TesseractとPyocrの導入後、画像の文字の認識が可能になります。
ここでは、次の画像を使用します。

以下のコードはPythonを使用してOCRを実行し、指定した画像ファイルからテキストを抽出するためのものです。
ソースコード
import pyocr
from PIL import Image
#pyocrにTesseractを指定する。
pyocr.tesseract.TESSERACT_CMD = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
tools = pyocr.get_available_tools()
tool = tools[0]
image =Image.open('test01.png') #画像ファイルを読み込む
text = tool.image_to_string(image, lang="jpn", builder=pyocr.builders.TextBuilder()) #画像の文字を抽出
print(text) # 抽出したテキストを表示UdemyでPythonを学習
Udemyは、オンデマンド式の学習講座です。
趣味から実務まで使えるおすすめの講座を紹介します。
- 現役シリコンバレーエンジニアが教えるPython 3 入門 + 応用 +アメリカのシリコンバレー流コードスタイル
Pythonをインストールから環境設定、基本文法が学習
さらに暗号化、インフラ自動化、非同期処理についても学べます。
Pythonを基礎から応用まで学びたい人におすすめ
- みんなのAI講座 ゼロからPythonで学ぶ人工知能と機械学習 【2024年最新版】
機械学習ライブラリで文字認識や株価分析などを行う。
人口知能やニューラルネットワーク、機械学習を学びたい人におすすめ。
- 【世界で55万人が受講】データサイエンティストを目指すあなたへ〜データサイエンス25時間ブートキャンプ〜
統計分析、機械学習の実装、ディープラーニングの実装を学習。
データサイエンティストになりたい人におすすめ。
- 0から始めるTkinterの使い方完全マスター講座〜Python×GUIの基礎・応用〜
TkinterのGUIを作成から発展的な操作までアプリ実例を示して学習。
アプリ開発したい人におすすめ。
解説
pyocrライブラリはPythonのOCRツールのラッパーライブラリで、
テキストを画像から抽出するために使用します。
PILライブラリはPython Imaging Libraryの略で、画像処理に使用します。
import pyocr
from PIL import ImageTesseract OCRエンジンの実行ファイルのパスを指定し、Tesseractをコマンドラインから呼び出すために必要です。
また、pyocr.get_available_tools() を使用して、利用可能なOCRツールを取得、そのうちの最初のツールを選択しています。
一般的に、Tesseractが最初に利用可能なツールとしてリストに表示されます。
pyocr.tesseract.TESSERACT_CMD = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
tools = pyocr.get_available_tools()
tool = tools[0]PILライブラリを使用し、指定されたファイルパスにある画像ファイル(’test01.png’)を開きます。
tool.image_to_string() メソッドを使用して、指定された画像からテキストを抽出します。
また、本メソッドの引数は、「image」、「lang」、「builder」です。
- image: OCRを実行する対象の画像。
- lang=”jpn”: OCRの言語設定。ここでは、日本語を指定しています。
- builder=pyocr.builders.TextBuilder(): 抽出されたテキストを加工するためのビルダーオブジェクトを指定しています。ここでは、テキストを生のテキストとして取得します。
最後に抽出されたテキストをコンソールに表示します。
image =Image.open('test01.png') #画像ファイルを読み込む
text = tool.image_to_string(image, lang="jpn", builder=pyocr.builders.TextBuilder()) #画像の文字を抽出実演
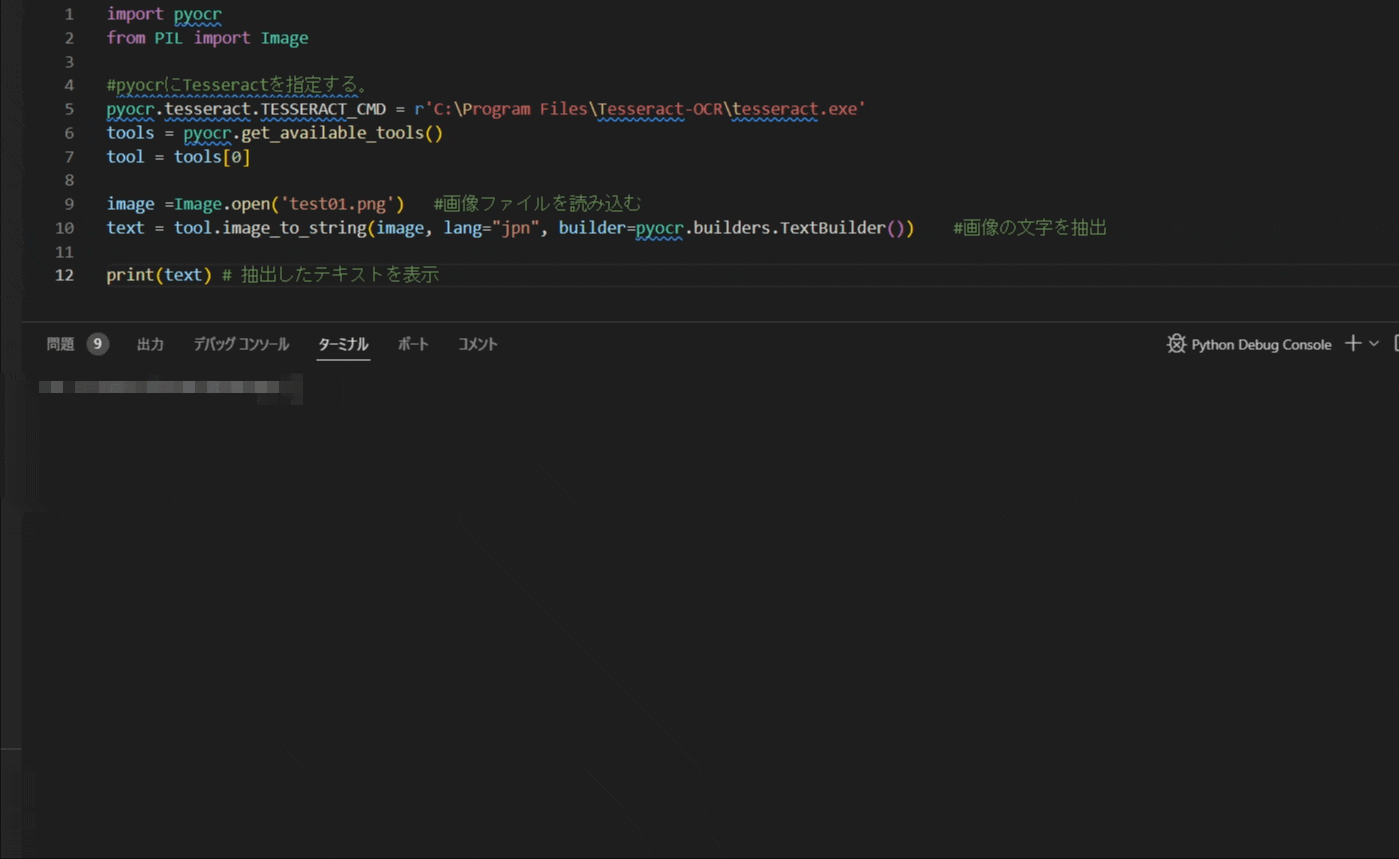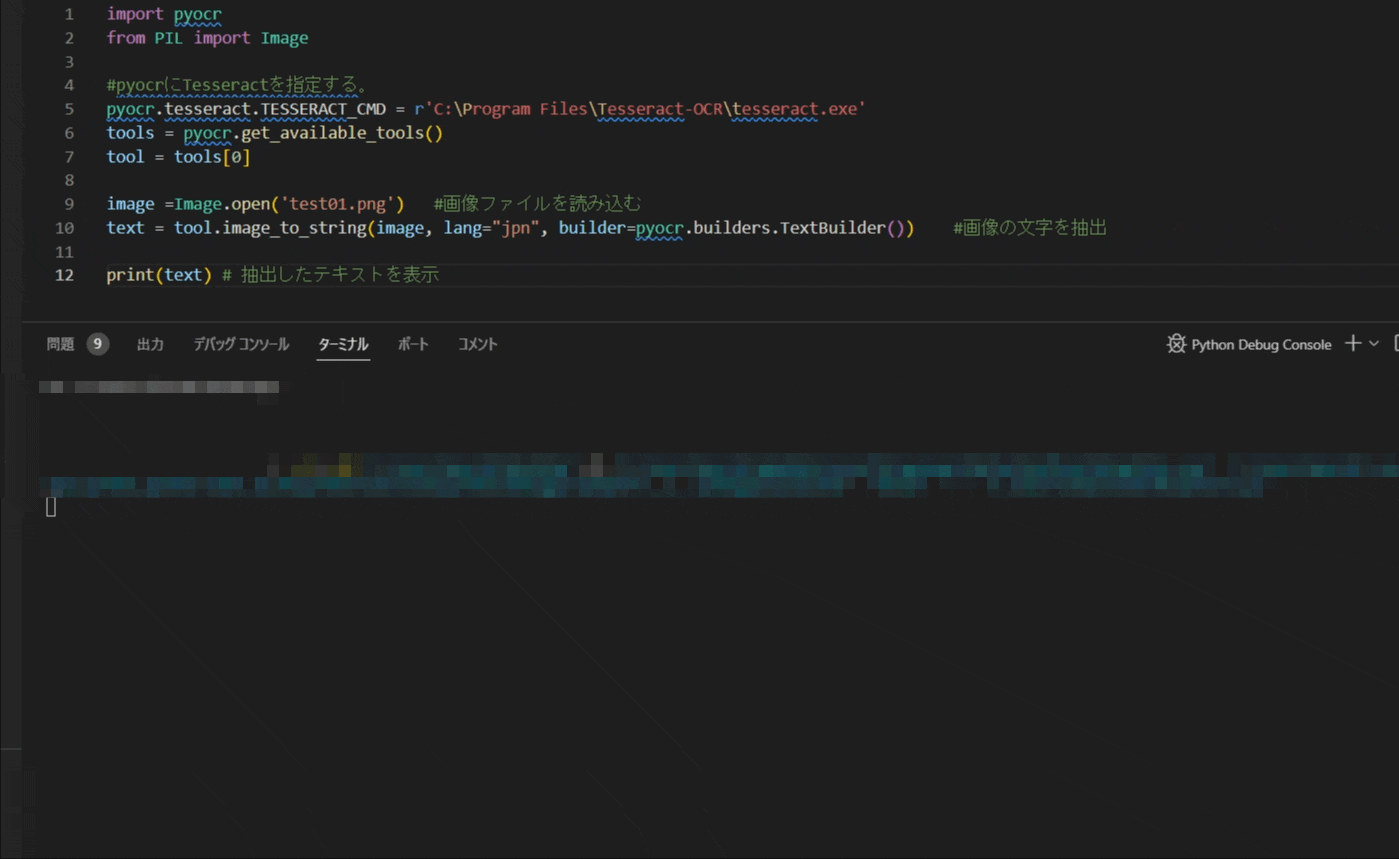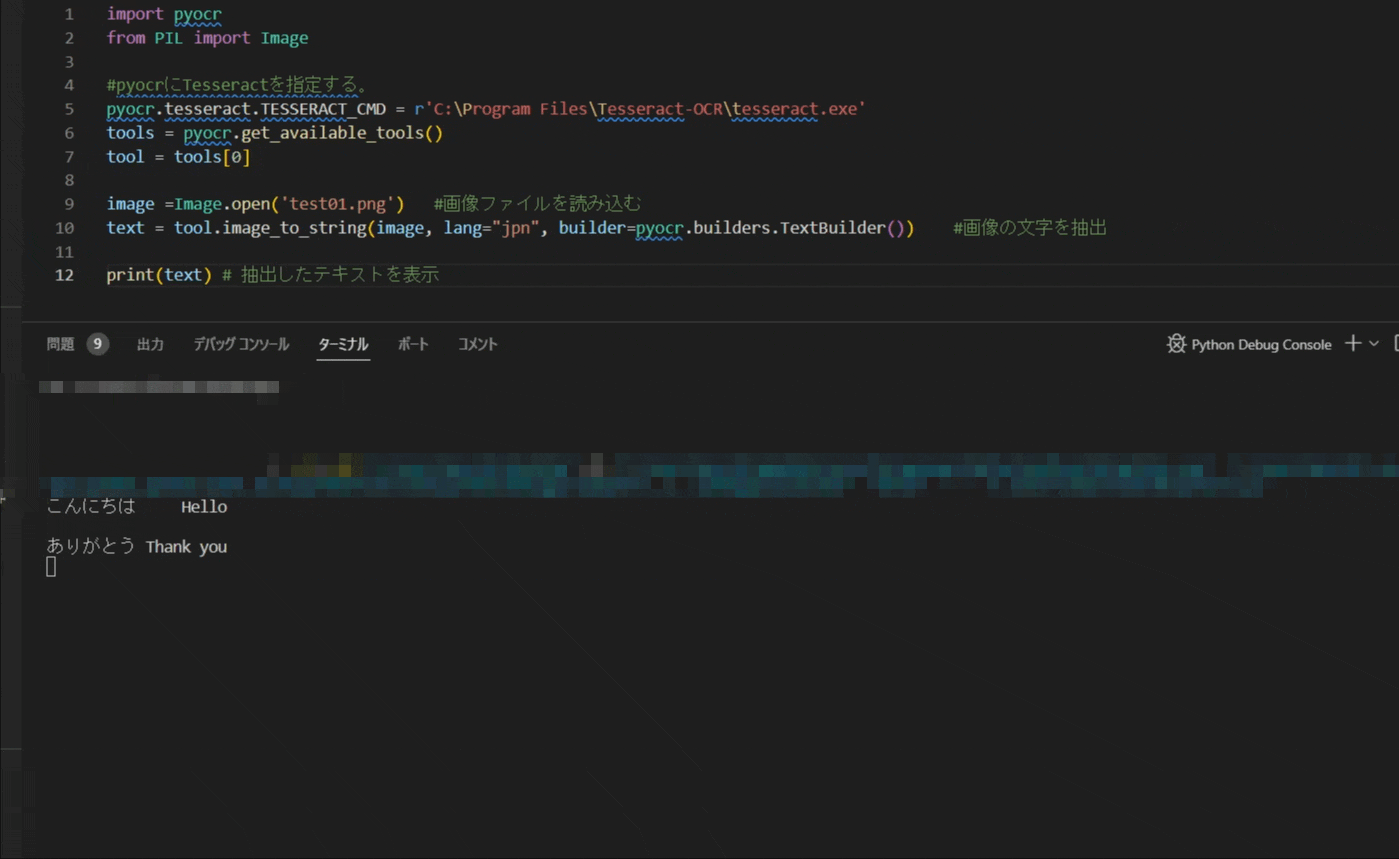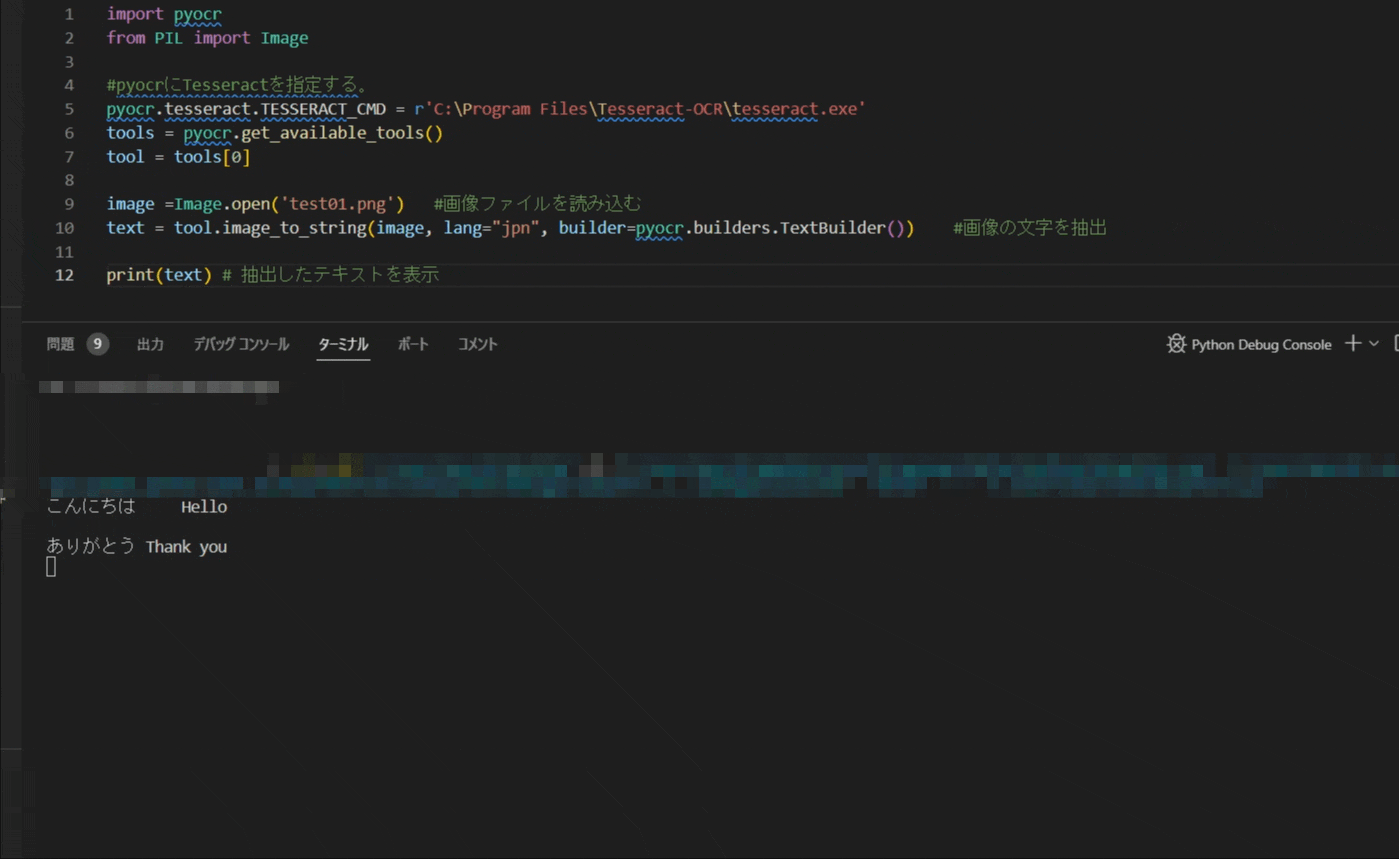
それでは、紹介したコードを実行します。
VScodeでスクリプトを実行すると冒頭のような処理ができます。
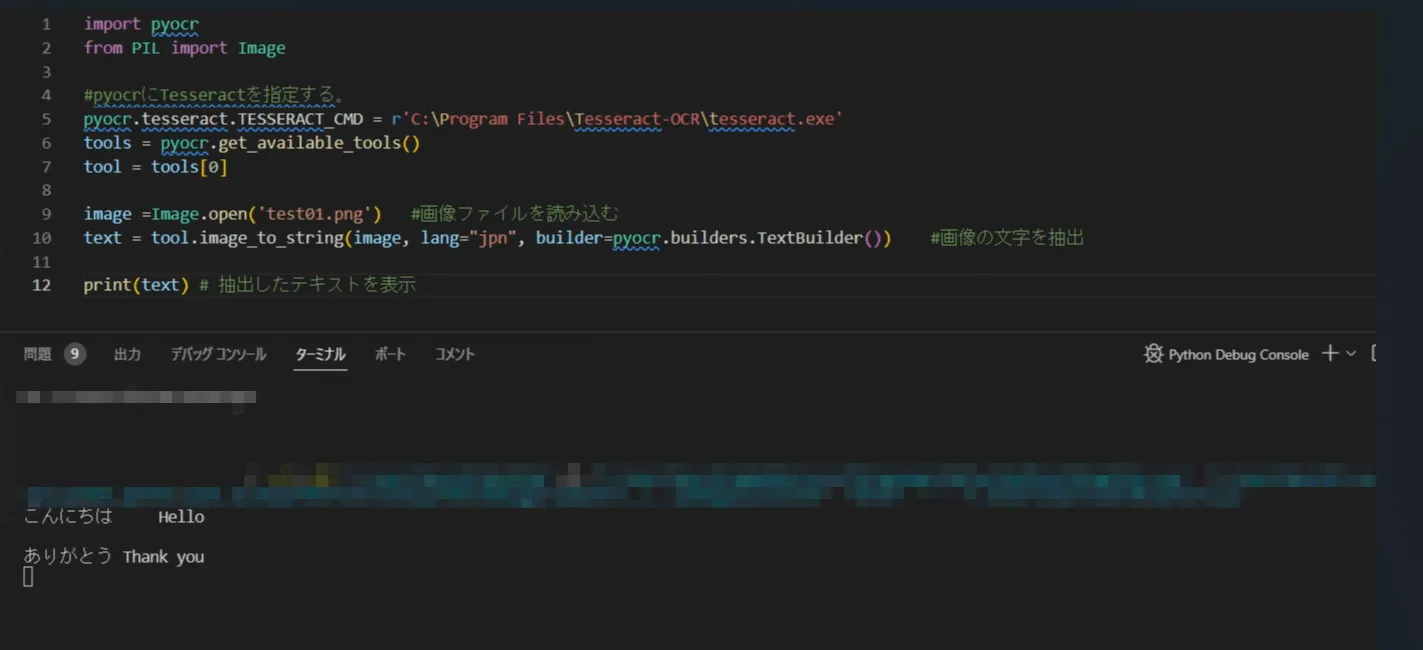
日本語で設定していましたが、ローマ字もしっかりと認識できるので、英語もコンソールに抽出されます。
pythonのocr機能を高精度にしたい
今回の実行では、日本語と英語をしっかりと認識することができました。しかし、文字認識が間違いだらけになってしまうことも多々あります。
可能な限り正しく文字を出力するには、画像の質を上げることが最も身近で「解像度を上げる」、「ノイズを除去」する必要があります。
次のコードは、ノイズ除去とリサイズをしてOCRの精度を向上させるコードです。
追加で二値化処理(画像を白と黒に変換する技術)を行うことでより一層文字認識を正確にしています。
from PIL import Image, ImageFilter
import cv2
import numpy as np
# 入力画像のパス
input_path = "input_image.png"
output_path = "processed_image.png"
# OpenCVで画像を読み込み(グレースケール化)
img = cv2.imread(input_path, cv2.IMREAD_GRAYSCALE)
# ノイズ除去(ガウシアンブラーや中央値フィルター)
img = cv2.medianBlur(img, 3) # 小さなノイズを除去
# 二値化処理(OCRの精度が上がる)
_, img = cv2.threshold(img, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)
# 解像度アップ(リサイズ)
scale_factor = 2 # 2倍に拡大
height, width = img.shape
resized_img = cv2.resize(img, (width * scale_factor, height * scale_factor), interpolation=cv2.INTER_CUBIC)
# 保存
cv2.imwrite(output_path, resized_img)
print(f"処理済み画像を保存しました: {output_path}")
pdfファイルをOCRする方法
PDFファイルは、Wordのような文書作成ツールであれば文字をコピーできますが、スキャンした画像をPDF化したファイルであると文字のコピーはできません。
画像だけのPDFを「検索可能なPDF」に変換するには、OCRmyPDFを使うことが非常に高価的です。1ページだけではなく複数ページ対応しており、Tesseractと連携で日本語を含む多言語を認識できます。
書類スキャンPDFをテキスト検索可能にしたい人、電子書籍の画像PDFにOCRをかけたい人、プログラムで定期的にOCRを自動処理したい人などにおすすめなパッケージです。
まとめ
OCR(光学文字認識)は、画像の文字を認識して、テキストのデジタルデータへと変換する技術のことをいいます。
書類や書籍などアナログ情報をデータ化するニーズが高まっていて、OCRの需要は拡大していきます。
自分のPCでOCRを使用するには、ヒューレット・パッカード(HP)が開発を進め、Googleが後援している光学式文字認識エンジンTesseractのインストールが必要です。
Windowsの場合は、exeファイル。Macの場合は、Homebrewを使用してTesseractを導入します。
また、Pythonで使う場合は、OCRエンジンと統合するPythonラッパーライブラリPyOCRのインストールが必要です

