

Pythonでテキストを音声として読み上げたいときには、
オフラインで動作する合成音声ライブラリ「pyttsx3」を使うと便利です。
このライブラリは、簡単にテキストを音声に変換でき、速度や音声の種類も調整可能です。
プログラムにナレーションを追加したり、読み上げアプリを開発したりする際に活躍します。
本記事では、pyttsx3の基本的な使い方から、商用利用の可否や対応言語について詳しく解説します。
公式サイト:「Pyttsx3公式ページ」
- Pythonでテキスト読み上げ機能を実装したい人
- オフラインで動作する音声合成ライブラリを探している人
- 商用利用可能な音声合成ツールを検討している人
- Pythonでナレーション付きのアプリケーションを作成したい人
- 朗読ソフトや支援ツールを自作したい人
pyttsx3とは?

pyttsx3は、Python用のテキスト読み上げライブラリで、
コンピュータのローカルで音声合成を行います。
インストールは、コマンドプロンプト、ターミナルでできます。
pip install pyttsx3WindowsではSAPI5、MacOSではNSSpeechSynthesizer、Linuxではespeakを使用しており、
さまざまなプラットフォームで簡単に利用できます。pyttsx
| Windows | sapi5 |
| Mac | nsss |
| Linux | espeak |
また、音声速度や音量、性別の調整が可能で、カスタマイズ性が高い点も特徴です。
音声の読み上げ
テキストをリアルタイムで音声として再生できます。
say()メソッドにテキストを入力し、runAndWait()メソッドで実行します。
import pyttsx3
# エンジンの初期化
engine = pyttsx3.init()
# 読み上げるテキスト
engine.say("Hello, I am reading this text.")
# 読み上げ実行
engine.runAndWait()
音声のプロパティ変更
音声の再生速度、音量、音声の性別など、細かいプロパティを変更できます。
カスタマイズした音声合成が可能です。
速度150で音量90%、男性の声で「Hello alicia-ing」と読み上げます。
import pyttsx3
engine = pyttsx3.init()
# 音量の設定(0.0 から 1.0)
engine.setProperty('volume', 0.9)
# 速度(WPM: words per minute)
engine.setProperty('rate', 150)
# 音声(性別)の変更
voices = engine.getProperty('voices')
engine.setProperty('voice', voices[0].id) # 男性の声
#engine.setProperty('voice', voices[1].id) # 女性の声
engine.say("Hello alicia-ing")
engine.runAndWait()音声の保存
テキストを音声ファイル(WAV形式)として保存することができます。
save_to_file()メソッドを使用して、音声をファイルに書き出すことが可能です。
ただし、mp3ファイルは非対応です。
text= "Hello alicia-ing"
engine.save_to_file(text , 'voice.wav')イベント制御
読み上げ開始、終了時にイベントをトリガーにして、プログラムを処理する。
再生が開始したら、「Start」とログを出力し、
再生が終了したら、「製作者と終わった時間」を取得して、ログに出力する。
import pyttsx3
from datetime import datetime
def onStart(name):
print("Start")
def onEnd(name, completed):
end_time = datetime.now().strftime("%H:%M:%S") # 再生終了時刻を取得
print(f"End, presented: {name}, completed at: {end_time}")
engine = pyttsx3.init()
# イベントの接続
engine.connect('started-utterance', lambda name: onStart("Alicia"))
engine.connect('finished-utterance', lambda name, completed: onEnd("Alicia", completed))
# 読み上げの設定と実行
engine.say("This will trigger events.")
engine.runAndWait()
商用利用可能か?

pyttsx3はオープンソースライブラリであり、商用利用も可能です。
ただし、音声エンジンに依存する部分もあるため、
合成音声エンジン自体のライセンス条件を確認する必要があります。
そのため、商用利用可能なGoogle-Text-to-Speechがおすすめです。
APIを取得すれば、Pythonからも操作できます。

対応している言語は?

pyttsx3は、使用する音声エンジンに依存して、様々な言語に対応しています。
具体的には、英語、日本語、フランス語、ドイツ語など、多くの言語で音声合成が可能です。
ただし、エンジンやOSによっては、言語のサポート状況が異なります。
Windowsでは、英語、日本語、フランス語はできた。ドイツ語もできたが英語?ってなった。
韓国語は発音できず、中国語は違う気がした。
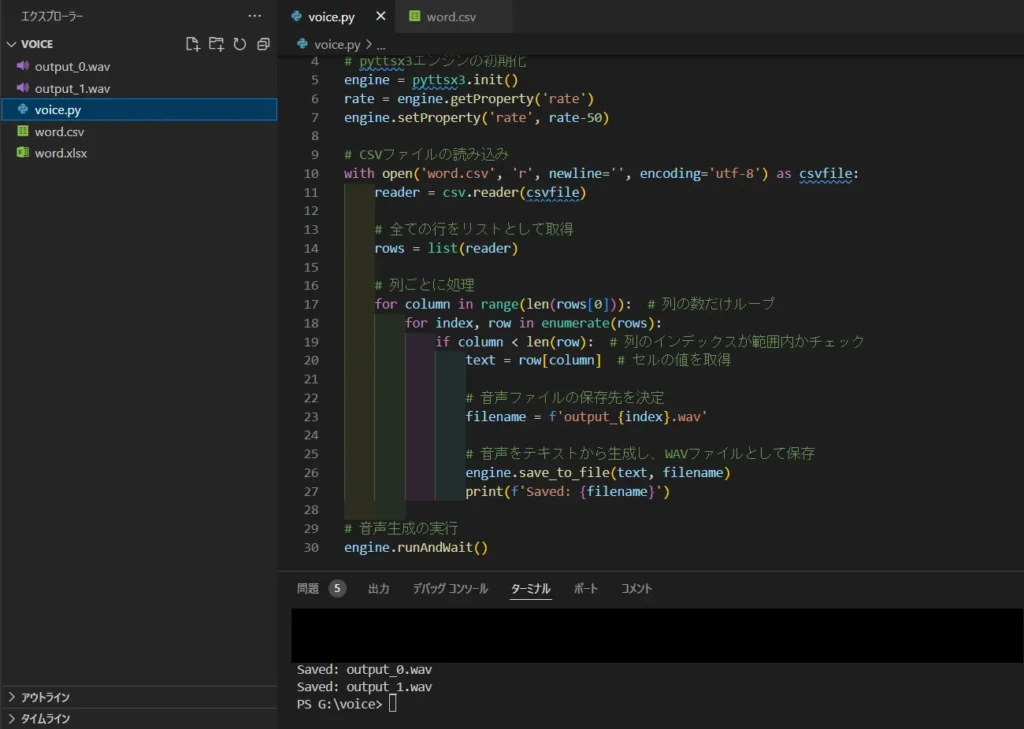
csvのテキストを一括でwavファイル化

pyttsx3を使用してCSVファイル内のテキストを一括で音声にします。
ソースコード
import pyttsx3
import csv
# pyttsx3エンジンの初期化
engine = pyttsx3.init()
rate = engine.getProperty('rate')
engine.setProperty('rate', rate-50)
# CSVファイルの読み込み
with open('word.csv', 'r', newline='', encoding='utf-8') as csvfile:
reader = csv.reader(csvfile)
# 全ての行をリストとして取得
rows = list(reader)
# 列ごとに処理
for column in range(len(rows[0])): # 列の数だけループ
for index, row in enumerate(rows):
if column < len(row): # 列のインデックスが範囲内かチェック
text = row[column] # セルの値を取得
# 音声ファイルの保存先を決定
filename = f'output_{index}.wav'
# 音声をテキストから生成し、WAVファイルとして保存
engine.save_to_file(text, filename)
print(f'Saved: {filename}')
# 音声生成の実行
engine.runAndWait()UdemyでPythonを学習
Udemyは、オンデマンド式の学習講座です。
趣味から実務まで使えるおすすめの講座を紹介します。
- 現役シリコンバレーエンジニアが教えるPython 3 入門 + 応用 +アメリカのシリコンバレー流コードスタイル
Pythonをインストールから環境設定、基本文法が学習
さらに暗号化、インフラ自動化、非同期処理についても学べます。
Pythonを基礎から応用まで学びたい人におすすめ
- みんなのAI講座 ゼロからPythonで学ぶ人工知能と機械学習 【2024年最新版】
機械学習ライブラリで文字認識や株価分析などを行う。
人口知能やニューラルネットワーク、機械学習を学びたい人におすすめ。
- 【世界で55万人が受講】データサイエンティストを目指すあなたへ〜データサイエンス25時間ブートキャンプ〜
統計分析、機械学習の実装、ディープラーニングの実装を学習。
データサイエンティストになりたい人におすすめ。
- 0から始めるTkinterの使い方完全マスター講座〜Python×GUIの基礎・応用〜
TkinterのGUIを作成から発展的な操作までアプリ実例を示して学習。
アプリ開発したい人におすすめ。
解説
- モジュール名
「pyttsx3」:Pythonのテキストを音声に変換するためのライブラリ。テキストを音声ファイルに保存する機能が必要なため使用している。
「csv」:CSV(Comma-Separated Values)形式のファイルを読み込み、テキストデータを取得するために使用される。
Python標準ライブラリなので、インストール不要。
- フィールド(メンバ変数)
「engine」:pyttsx3のエンジンを初期化し、音声合成のためのインスタンスを作成する。
「rate」:音声の速度を取得するために使用。通常のスピードよりも遅くするため、rate-50に設定される。
「csvfile」:CSVファイルを読み込むためのファイルオブジェクト。
「reader」:csv.readerによって、CSVファイルの内容を行ごとに読み込むリーダーオブジェクト。
「rows」:CSVファイルの全ての行をリストとして保持する。各行はリストの形式で格納される。
「index」:音声ファイルを保存するための番号。
「column」:CSVファイルの列インデックスを管理する変数。各列のデータを処理するために使われる。
「row」:CSVファイルの各行を指す変数。リスト形式で保持された各行のデータを処理するために使われる。
「text」:現在のセル(CSVの特定の行・列)の値をテキストとして保持する。
「filename」:音声ファイルを保存する際のファイル名。処理されているセルに基づき生成される。
- 関数・メソッド
「pyttsx3.init()」:音声エンジンを初期化し、音声合成のためのエンジンインスタンスが生成される。
「engine.getProperty(‘rate’)」:現在設定されている音声の読み上げ速度を取得する。音声の読み上げ速度をカスタマイズするために使用される。
「engine.setProperty(‘rate’, rate-50)」:音声の読み上げ速度をrate-50に設定する。pyttsx3は読み上げ速度が速すぎるので、半分ぐらいがおすすめ。
「csv.reader()」:CSVファイルを読み込み、行ごとのデータを取得するためのリーダーオブジェクトを返す。
「engine.save_to_file(text, filename)」:textで指定したテキストを音声に変換し、指定したファイル名filenameでWAV形式の音声ファイルに保存する。
「engine.runAndWait()メソッド」:すべての音声を処理し、音声合成を実行する。全てのテキストの音声化が完了するまで待機する。
- その他
with open():CSVファイルを読み込み、ファイル操作を行う。ファイルを開いた後は、自動的にクローズする。encoding=’utf-8’により、UTF-8形式でファイルを読み込む設定。
list(reader):csv.readerオブジェクトから全ての行をリスト形式で取得し、rowsに保存する。
enumerate()関数:各行をインデックス付きで処理するために使用される。ループ内で行インデックスを取得しつつ、その行自体も同時に扱う。
実演
スクリプトを実行すると、csv(word.csv)に保管してあるテキストを読み込み、
wav形式で保存します。
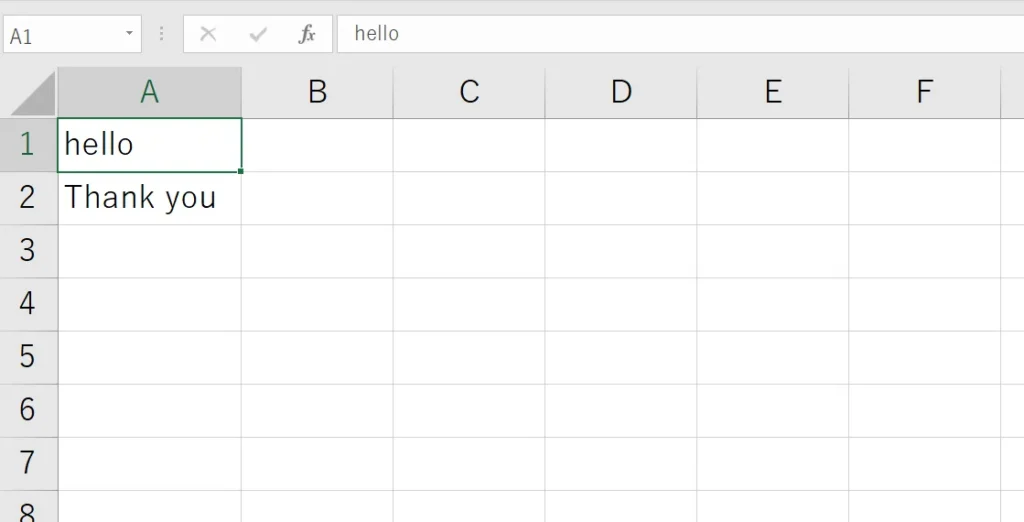
保存先は、Pythonのスクリプトと同じ段落です。
まとめ
Pythonの合成音声ライブラリ「pyttsx3」の基本的な使い方とその機能について解説しました。
pyttsx3は、テキストの読み上げから、音声ファイルの生成、プロパティの変更まで、幅広い用途に対応します。

