

Google Text-to-SpeechをPythonから制御する。
GoogleのText-to-Speech APIを使えば、
Pythonを用いて簡単にテキストを音声に変換できます。
本記事では初めての方にも分かりやすく、
APIの取得方法からPythonでの実装までを詳しく解説していきます。
また、商用利用や料金、音声ファイルの保存方法など、
Pythonで自動音声生成を行う手順を完全に理解できる内容となっています。
- Pythonでテキストを音声に変換したい方
- Google Text-to-Speechを使って多言語対応の発話システムを作りたい方
- 商用プロジェクトで音声合成を利用したいと考えている方
- 音声データを自動生成してMP3形式で保存したい方
- 教育コンテンツや自動ナレーションを簡単に作成したい方
Google Text-to-Speechとは

Google Text-to-Speechはテキストを音声に変換するサービスで、
無料で使える発話エンジンです。
日本語、英語、フランス語など、多くの言語に対応していて幅広い用途で利用できます。
Pythonと組み合わせることで、さまざまな音声アプリケーションを簡単に作成できます。
たとえば、ナビゲーションシステムや教育アプリ、自動応答システムなど用途は無限大です。
Google Text-to-SpeechはAI技術を駆使して、自然で高品質な音声を生成します。
これにより、ユーザーにとって使いやすく、聞き心地の良い音声を提供することが可能です。
また、Text-to-Speechはアクセントや話者のトーンなども調整可能なため、
さまざまな音声タイプをカスタマイズできます。
Google Text-to-Speechの使い方
Google Text-to-Speechを使うには、まずGoogle Cloudのアカウントを作成し、
Text-to-Speechを有効にする必要があります。
Pythonのプログラムから音声合成を行うためには、
Google Cloudの認証情報(APIキー)を取得して設定する必要があります。
Pythonコードを用いることで、指定したテキストを音声に変換し、
WAVやMP3形式で保存することが可能です。
これにより、手軽に音声ガイドやナレーションを自動生成することができます。
例えば、観光案内アプリでの音声案内や教育用の教材など、多種多様な用途で活用できます。
また、テキストの内容に基づいて発話速度やピッチも調整できるため、
さまざまなシチュエーションに対応した音声を生成することが可能です。
Google Text-to-Speechは商用利用できる?
Google Text-to-Speechは商用利用も可能です。
ただし、Google Cloudの使用量に応じた料金が発生するため、
商用プロジェクトで利用する際は料金体系に十分注意する必要があります。
また、Googleの利用規約に従って、適切に利用することが求められます。
商用利用する場合、特に注意すべきなのは利用料金と使用制限です。
料金は使用量に依存しているため、大量に音声を生成する場合は予算に応じて計画的に使うことが求められます。API使用数を確認しながら調整する必要があります。
また、商用利用に際しては、エンドユーザーに対する情報提供やプライバシーの保護に対しても責任を持つ必要があります。これらを十分に理解したうえで、商用利用を進めることが大切です。
pyttsx3との比較
合成音声pyttsx3の場合は、PC搭載の読み上げ機能を使うためAPIを必要としません。
ただし、pyttsx3自体は商用利用できますが、読み上げソフトが商用利用できません。

要するに、個人で合成音声を使いたい場合は、pyttsx3を使用して、
ゲームやアプリのナレーションに追加したい場合は、
Google Text-to-Speechを使う必要があります。
Google Text-to-Speechの料金(無料枠)は?
無料枠の利用では、月に400万文字(WaveNetは100万文字)まで音声合成が可能です。
それを超えた場合は従量課金制で料金が発生します。
商用利用を検討している場合、Google Cloudの料金表を確認し、
必要な予算を見積もっておくことが重要です。
料金は、使用する声の種類や文字数に依存します。
例えば、標準的な音声とWaveNet音声(より自然な音声)では料金が異なります。
WaveNet音声はより高品質ですが、その分料金が高くなります。
また、使用する言語や地域によっても料金が変動することがありますので、
事前に詳細を確認することをお勧めします。
Google Cloudの無料利用枠を活用することで、コストを抑えながらプロトタイプを作成したり、個人プロジェクトで利用する際には、無料枠で十分対応できるケースが多いです。
ビジネス規模での利用に関しては、必要な予算を正確に把握し、
適切なプランを選択することが重要です。
Google Text-to-SpeechはMP3保存できる?
Google Text-to-Speechの音声合成はをMP3形式で保存することが可能です。
Pythonからテキストを取得して、そのままMP3またはWAV形式で保存することができます。この機能を使うことで、簡単にナレーション用の音声ファイルを生成することが可能になります。
例えば、教育コンテンツやオーディオブックの自動生成にMP3保存機能を活用することができます。音声ファイルは高音質で保存され、聞き取りやすいものとなります。
また、MP3形式で保存することで、さまざまなデバイスで再生可能な音声ファイルを作成することができます。これにより、ユーザーの利便性を高めることができ、プロジェクトの成功に寄与します。
WAV形式に比べてMP3形式はファイルサイズが小さいため、
オンラインでの共有やストレージの節約にも有利です。
Pythonを使用してMP3形式に保存することで、
音声ファイルの管理が簡単になり、アプリケーションの効率的な運用が可能となります。
作成した動画にナレーションを入れたい場合、
moviepyを併用することで、簡単にナレーション音声を導入できます。

Google Text-to-Speechの登録方法

Google Text-to-Speechを使うにはまずGoogle Cloudのアカウントを作成します。
「Google Cloud」にアクセスして、アカウント情報や支払い方法を入力します。
Cloud Speech-to-Textを有効にして、APIを取得します。
アカウント作成
「Text-to-Speechの無料トライアル」にアクセスし、Googleアカウントを用いてログインします。
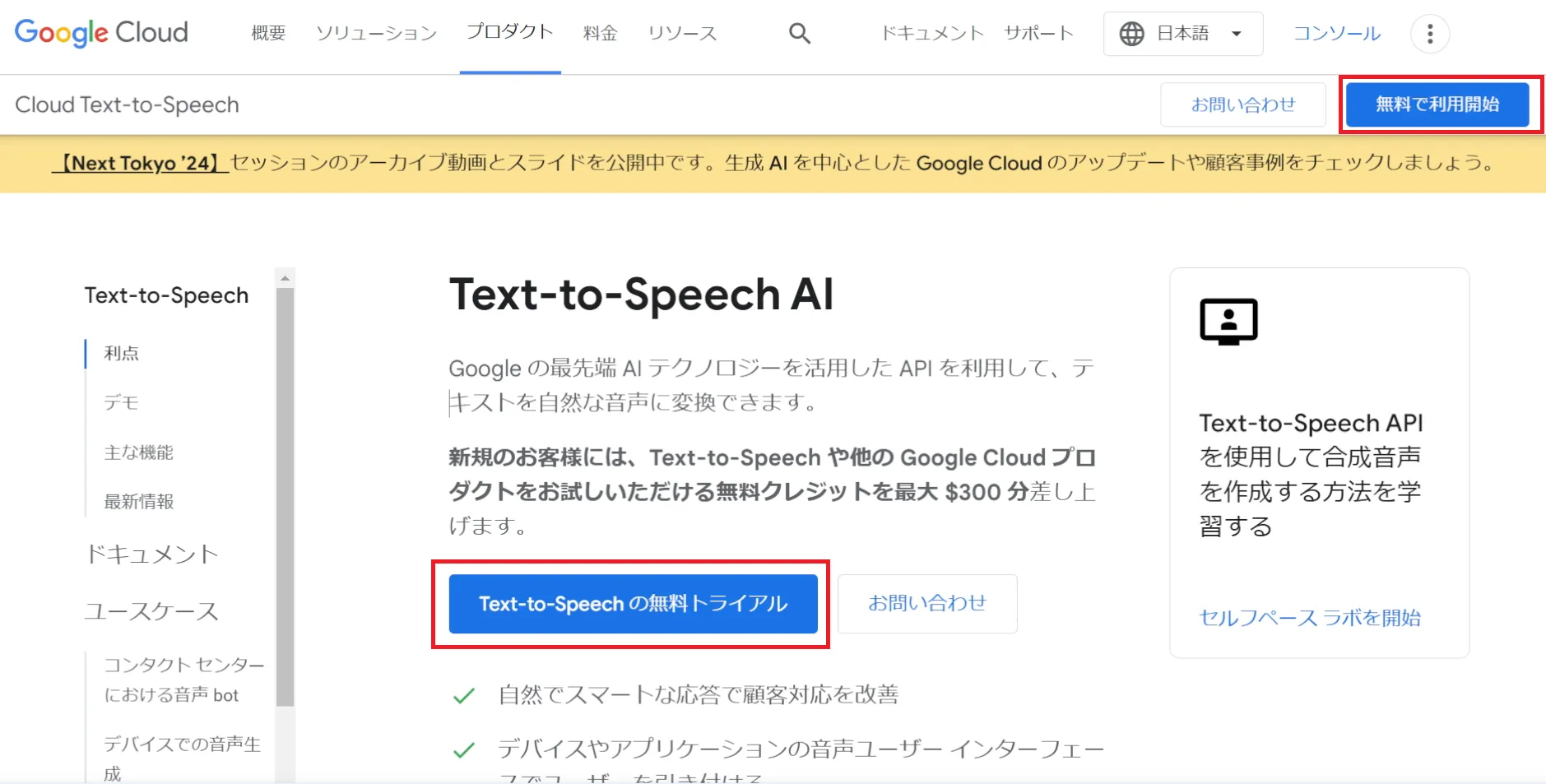
アカウント作成する際に、支払い方法を登録(クレジットカード・デビットカードなど)する必要があります。
既に、Google広告やアドセンスに登録している場合は、再度追加しなくてもよいです。
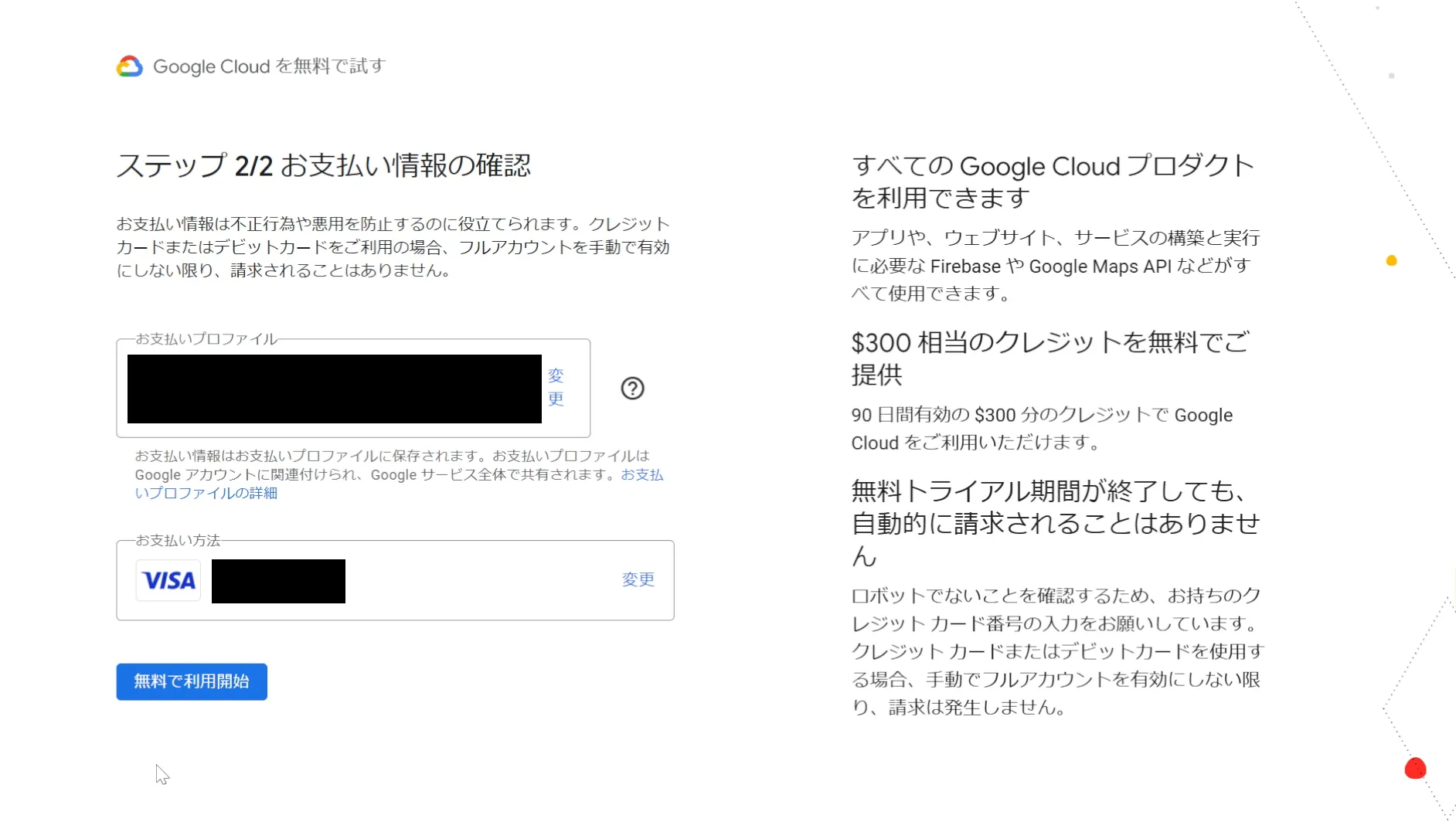
アカウント作成が完了したら、Google Cloudのさまざまなサービスを利用するための準備が整います。
プロジェクトの管理は、Google Cloudコンソールから簡単に行えます。
プロジェクトの概要や利用状況の確認、APIの有効化など、必要な操作を行うことで、プロジェクトをスムーズに進められます。
Text-to-Speechを有効にする
ハンバーガーメニューから「APIとサービス>ライブラリ」に移動して、
「Cloud Text-to-Speech API」を有効にします。
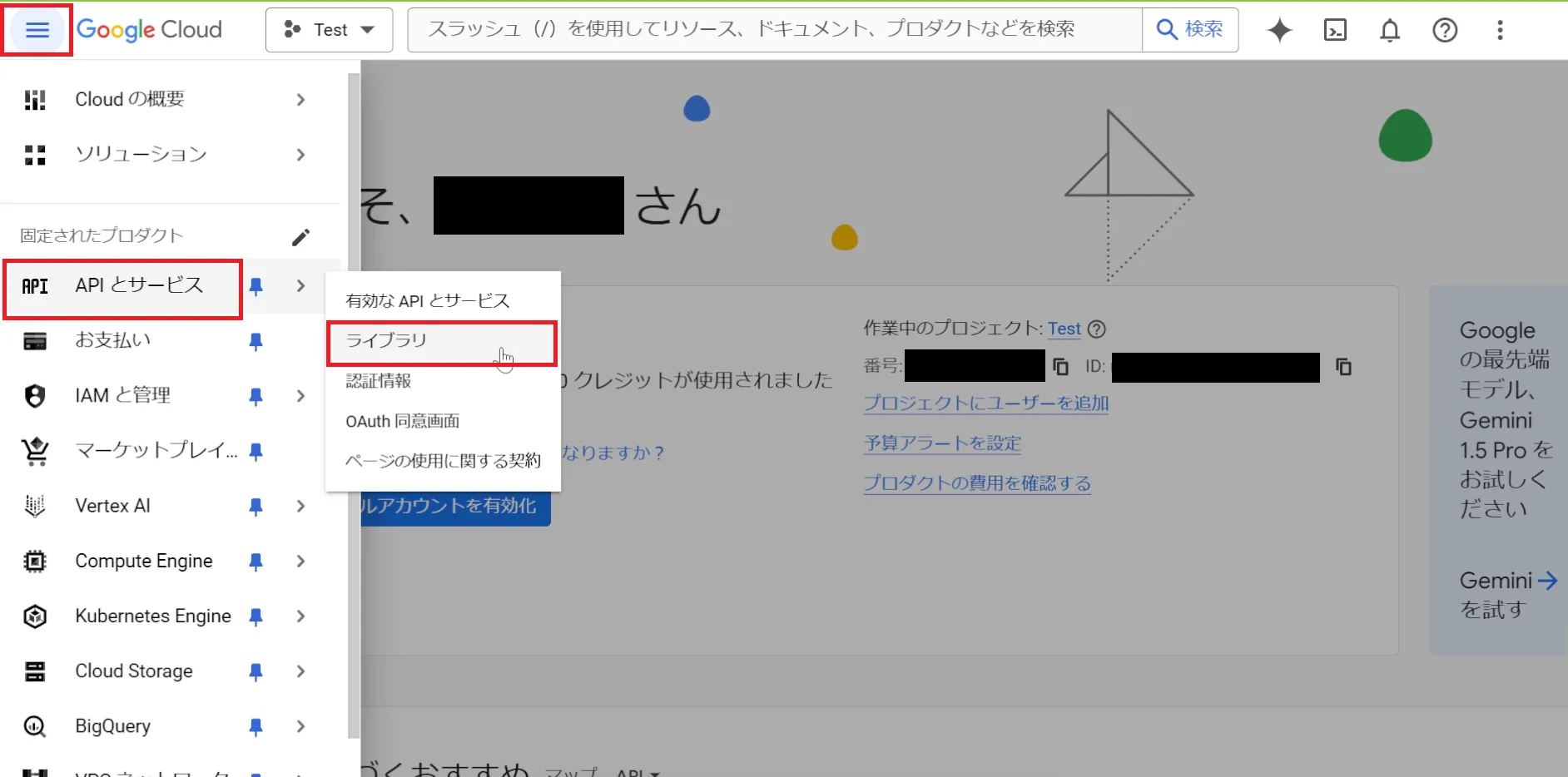
見つけることができない場合は、検索バーから探します。
Cloud Speech-to-Text APIというものがあります。
こちらは発話から文字に起こします。
動画の音声を字幕を自動で書き起こしたいときに使えます。
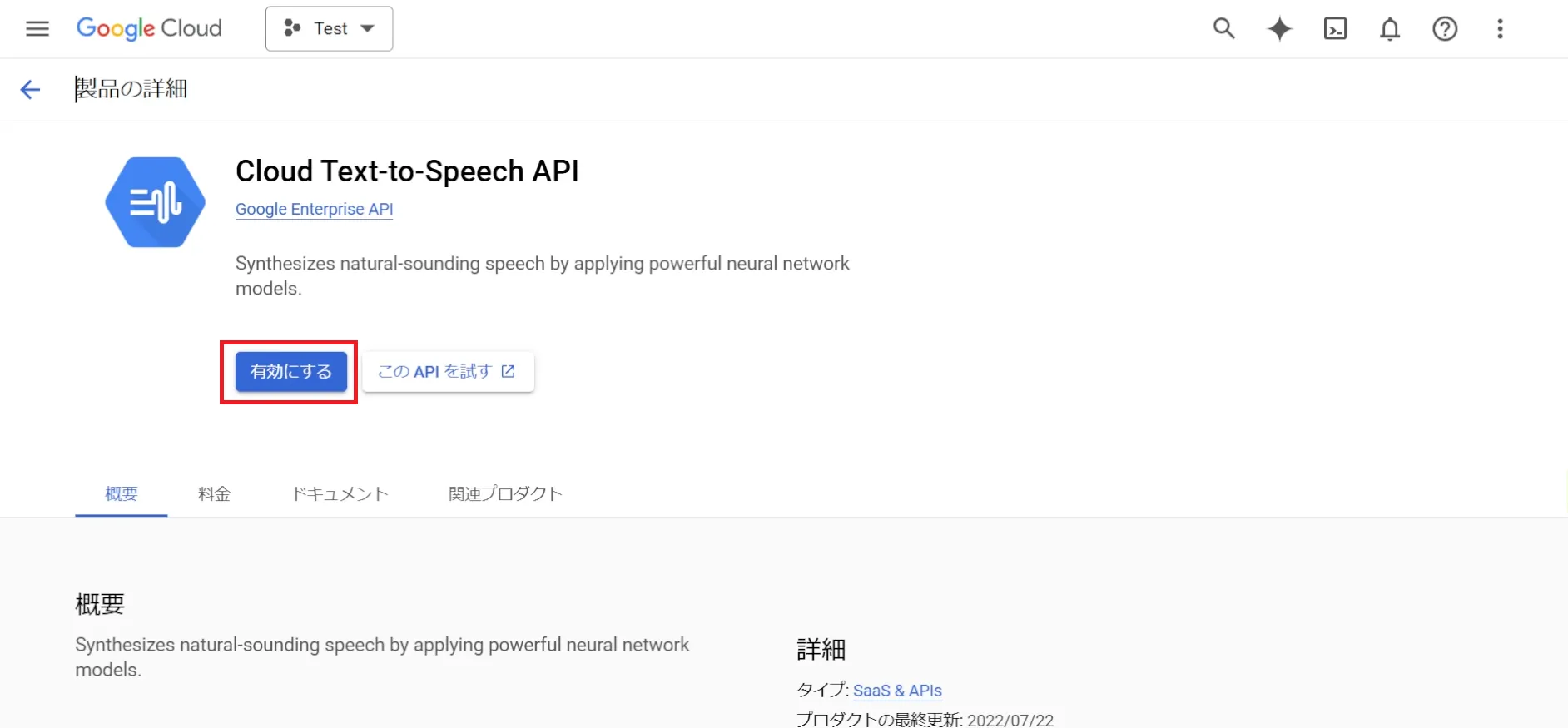
APIの有効化後、実際に音声合成のリクエストを行えるようになります。APIの有効化は簡単に行うことができ、あとは必要な認証情報を設定することでPythonから操作が可能です。
.jsonのAPIを取得
サイドバーから「IAMと管理>サービスアカウント」に進み、
サービスアカウントを作成します。
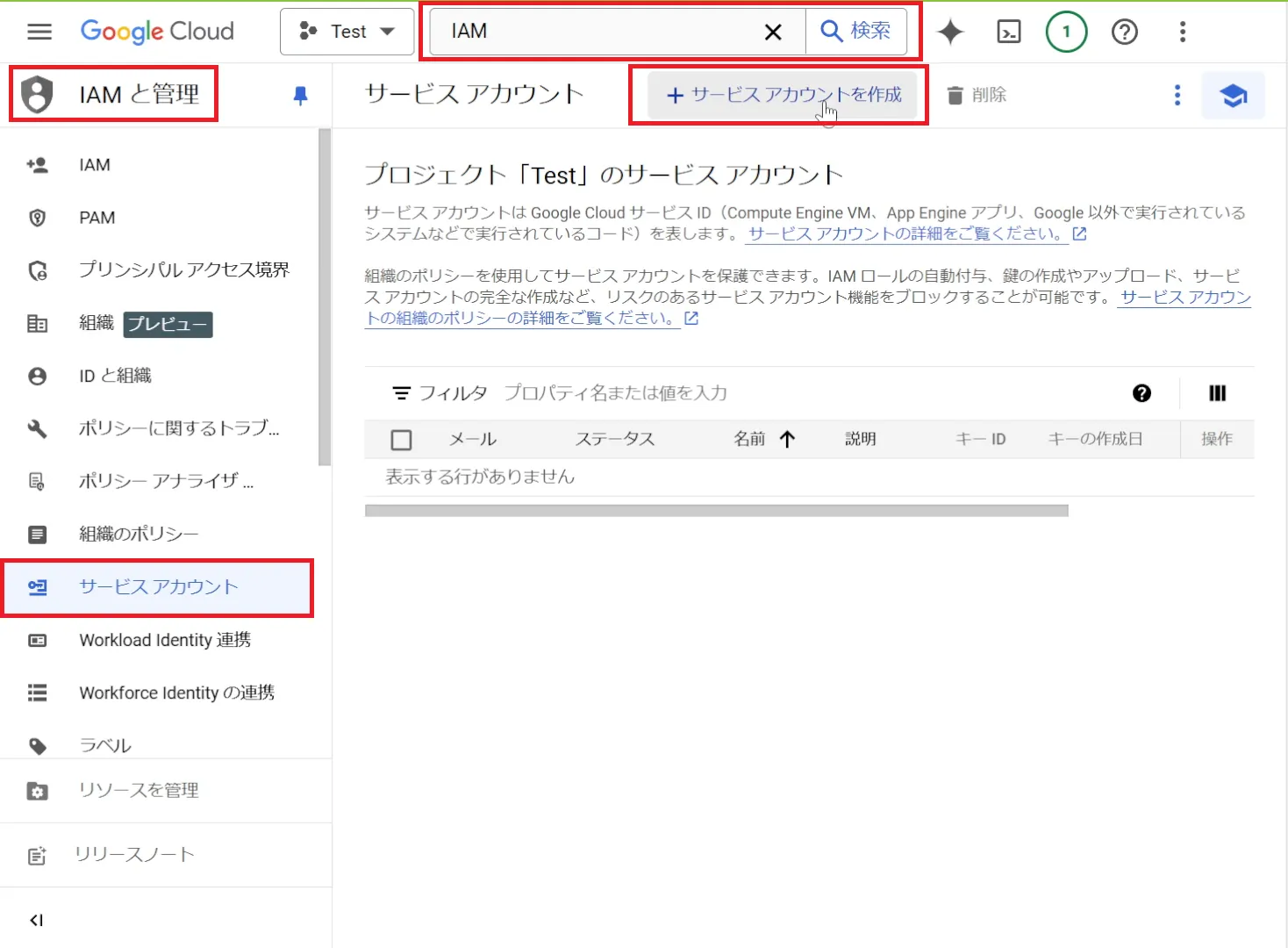
詳細情報に、サービスアカウント名を設定します。
指定すると自動でサービスアカウントIDが生成されます。
そのほかの情報は省略可能ですので、そのままで大丈夫です。
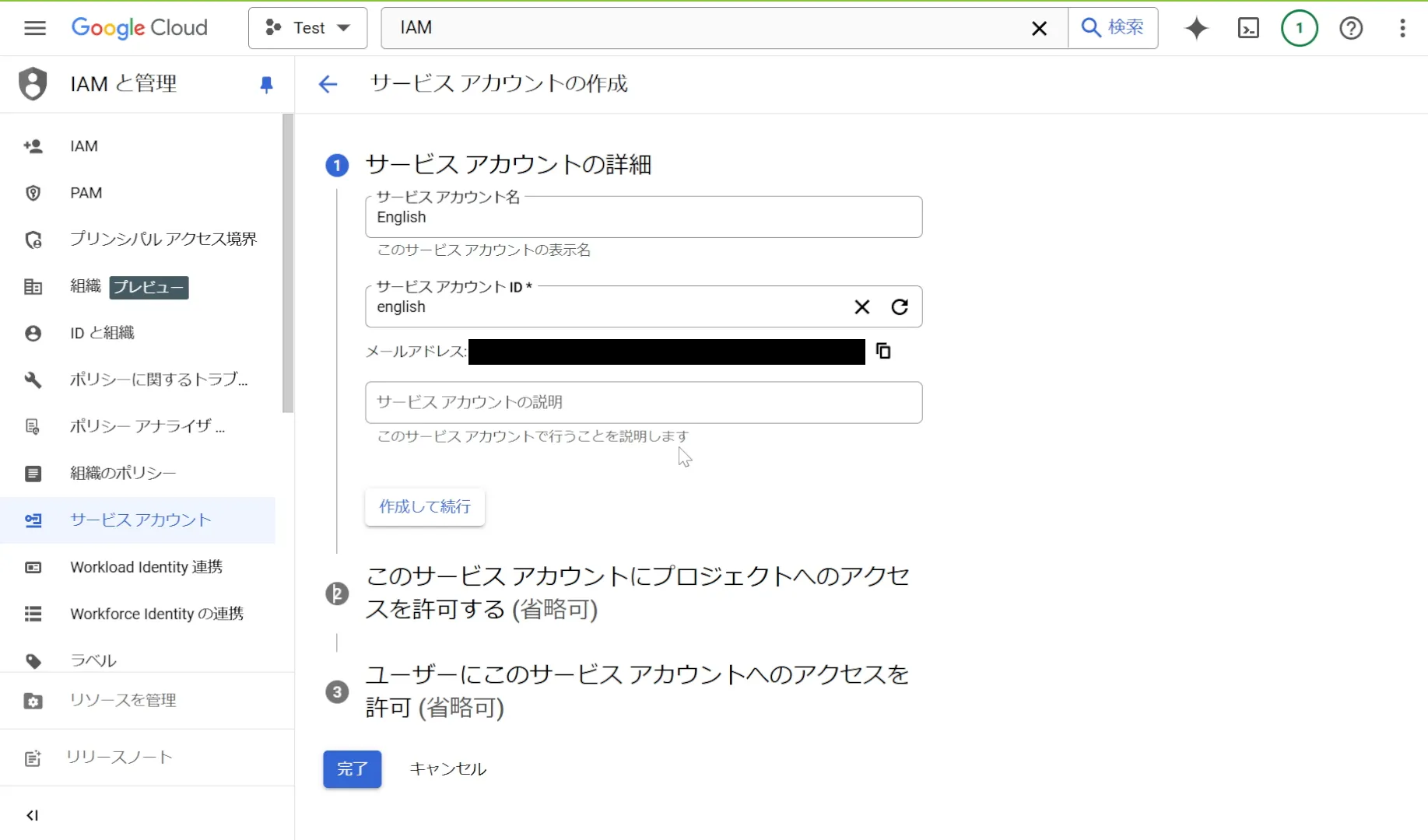
作成後、「操作」の3点マークから「鍵を管理」に進みます。
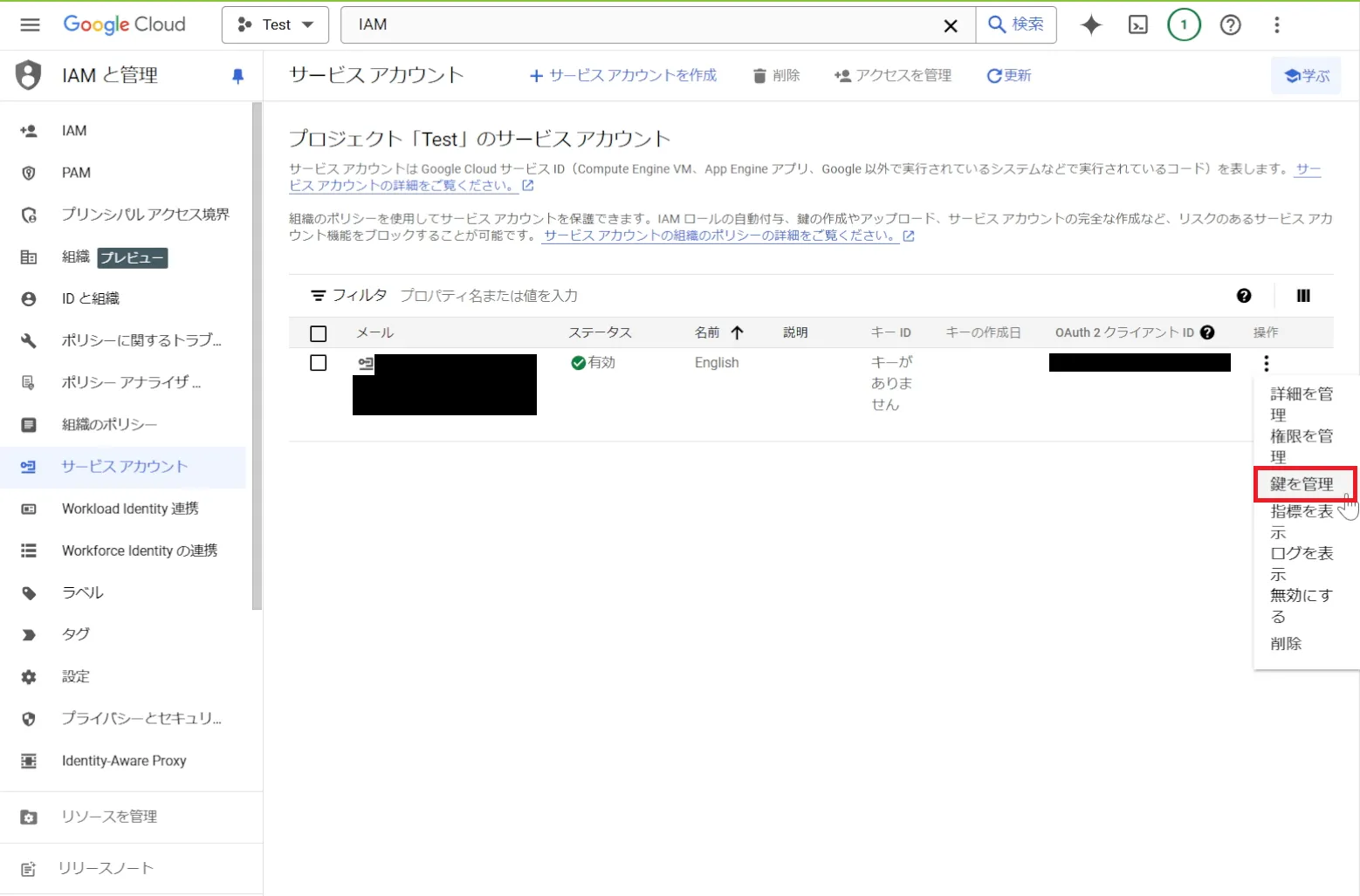
「キー」タブから「鍵を追加」を選択して、
JSONファイルを作成します。
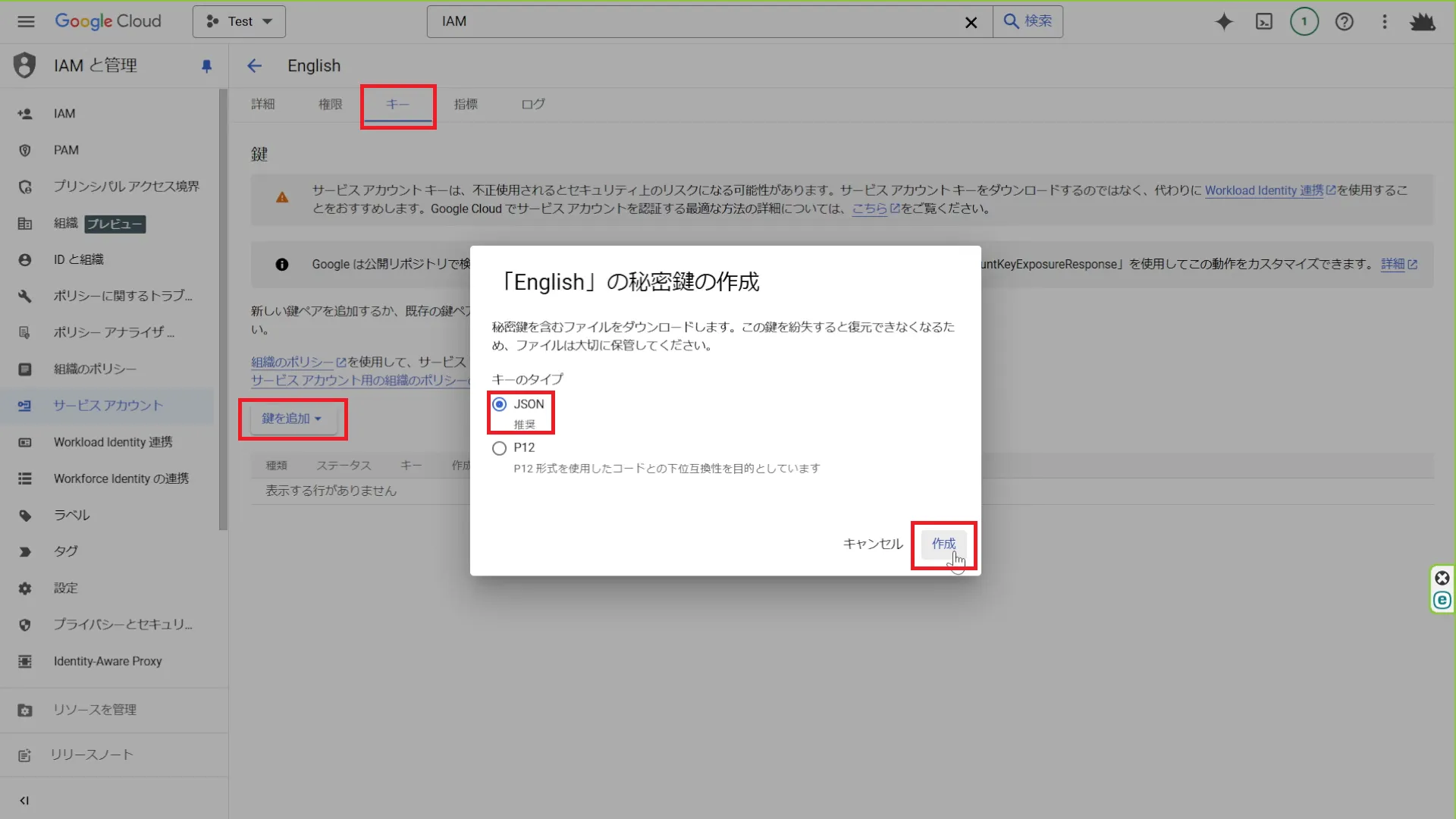
JSONファイルには、APIにアクセスするための認証情報が含まれています。
このファイルを適切に管理することで、安全にGoogle Cloudのサービスを利用することが可能です。Pythonスクリプトからこのファイルを参照することで、
音声合成のリクエストを安全に行うことができます。
PythonでGoogle Text-to-Speechを操作

Google Text-to-Speech APIをPythonで操作することで、
CSVファイルに格納したテキストを音声ファイルに変換することができます。
CSVのA列に英単語を格納してそれを一行ずつ読み込んで音声合成し、
WAVファイルとして保存することが可能です。
Pythonを使うことで、業務での自動化や学習教材の作成など、さまざまなシーンで活用できます。
特に、複数のテキストを一括で音声化したい場合に便利です。
例えば、数百行にわたるテキストデータを自動で音声ファイルに変換し、
ナレーションやガイドとして利用することができます。
手作業で音声を録音する手間を大幅に削減することができ、
生産性を向上させることができます。
また、教育機関での学習用資料の作成や、自動応答システムの開発にも応用できます。
ソースコード
import os
import csv
from google.cloud import texttospeech
# 認証情報のパスを設定
os.environ['GOOGLE_APPLICATION_CREDENTIALS'] = 'key.json'
# 音声生成関数
def generate_audio(csv_path):
# 保存先ディレクトリをCSVファイルと同じ場所に設定
save_directory = os.path.dirname(csv_path)
# Google Cloud TTSクライアントの作成
client = texttospeech.TextToSpeechClient()
# CSVファイルの読み込み
with open(csv_path, 'r', newline='', encoding='utf-8') as csvfile:
reader = csv.reader(csvfile)
# 各行のA列を順番に処理
for index, row in enumerate(reader):
if len(row) > 0: # A列に値があるか確認
word = row[0] # A列の単語を取得
# テキスト入力の設定
synthesis_input = texttospeech.SynthesisInput(text=word)
# 音声の設定(en-US-Standard-J話者を使用)
voice = texttospeech.VoiceSelectionParams(
language_code="en-US",
name="en-US-Standard-J"
)
# オーディオ設定
audio_config = texttospeech.AudioConfig(
audio_encoding=texttospeech.AudioEncoding.LINEAR16 # WAVフォーマット
)
# 音声合成のリクエスト
response = client.synthesize_speech(
input=synthesis_input,
voice=voice,
audio_config=audio_config
)
# ファイル名をインデックスと単語で作成し、保存先パスを設定
filename = os.path.join(save_directory, f'{index+1}_{word}.wav')
# 音声データの保存
with open(filename, 'wb') as out:
out.write(response.audio_content)
print(f'Saved: {filename}')
# メイン処理
if __name__ == "__main__":
# CSVファイルのパスを指定
csv_path = 'voice.csv'
# ファイルが存在するか確認
if os.path.exists(csv_path):
generate_audio(csv_path)
print("音声変換が完了しました。")
else:
print("エラー: 指定されたCSVファイルが存在しません。")UdemyでPythonを学習
Udemyは、オンデマンド式の学習講座です。
趣味から実務まで使えるおすすめの講座を紹介します。
- 現役シリコンバレーエンジニアが教えるPython 3 入門 + 応用 +アメリカのシリコンバレー流コードスタイル
Pythonをインストールから環境設定、基本文法が学習
さらに暗号化、インフラ自動化、非同期処理についても学べます。
Pythonを基礎から応用まで学びたい人におすすめ
- みんなのAI講座 ゼロからPythonで学ぶ人工知能と機械学習 【2024年最新版】
機械学習ライブラリで文字認識や株価分析などを行う。
人口知能やニューラルネットワーク、機械学習を学びたい人におすすめ。
- 【世界で55万人が受講】データサイエンティストを目指すあなたへ〜データサイエンス25時間ブートキャンプ〜
統計分析、機械学習の実装、ディープラーニングの実装を学習。
データサイエンティストになりたい人におすすめ。
- 0から始めるTkinterの使い方完全マスター講座〜Python×GUIの基礎・応用〜
TkinterのGUIを作成から発展的な操作までアプリ実例を示して学習。
アプリ開発したい人におすすめ。
解説
- モジュール名
「os」:ファイルシステムのパスや環境変数を扱うために使用されている。ここでは環境変数を設定し、CSVファイルの場所を扱うために必要。
「csv」:CSVファイルを読み込むために使用される。スクリプトでは、各行のA列の内容を音声生成のために取得する必要がある。
「google.cloud.texttospeech」:Google Cloud Text-to-Speech APIを利用するために必要。音声合成のリクエストを送るために使用されている。
- フィールド(メンバ変数)
「csv_path」:CSVファイルのパスを保持する。音声生成対象のファイルの場所を指定するために必要。
「save_directory」:音声ファイルの保存先ディレクトリのパスを保持する。CSVファイルと同じ場所に音声ファイルを保存するために使用。
「client」:Google Cloud Text-to-Speech APIクライアントのインスタンス。音声合成を行うために必要。
「word」:CSVファイルのA列から読み取った単語を保持する。この単語が音声合成の対象となる。
「synthesis_input」:音声合成に使用するテキストを保持する。Google Cloud Text-to-Speech APIに渡すために作成される。
「voice」:音声の設定を保持する。使用する言語コードと話者の情報が含まれ、どの話者を使って音声を生成するか指定する。
「audio_config」:オーディオ出力の設定を保持する。生成する音声のフォーマット(WAV形式)を指定する。
「filename」:生成した音声ファイルの保存先パスを保持する。インデックスと単語を使ってファイル名を作成。
generate_audioクラス
「csv_path」からCSVファイルを読み込み、A列の単語に対して音声を生成する関数。Google Cloud Text-to-Speech APIを利用して、各単語を音声ファイル(WAV形式)に変換し、CSVファイルと同じディレクトリに保存する。
まず「save_directory」をCSVファイルのディレクトリに設定し、APIクライアント「client」を生成する。
次に、CSVファイルを読み込み、各行に対してA列の単語を取得する。取得した単語を「synthesis_input」として設定し、音声の設定「voice」とオーディオ出力の設定「audio_config」を指定して「synthesize_speech」メソッドを呼び出し、音声を生成する。
最後に、生成した音声データを「filename」に保存する。ファイル名にはインデックスと単語を使っており、保存先ディレクトリに「.wav」ファイルとして保存する。
本ソースコードでは、「voice.csv」と先に指定しているが、
Tkinterを使うことでユーザーの設定によって決めることもできる。

実演
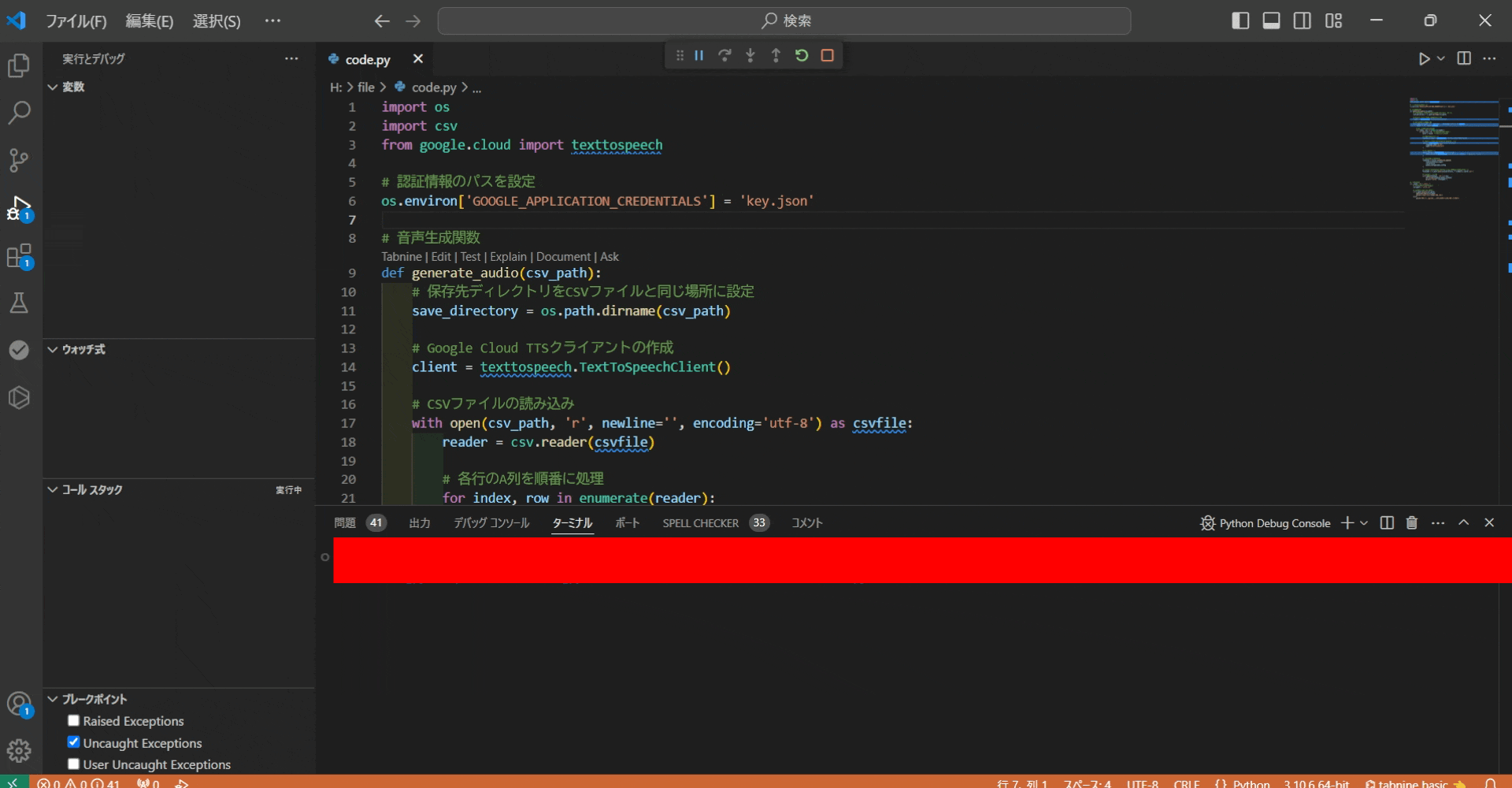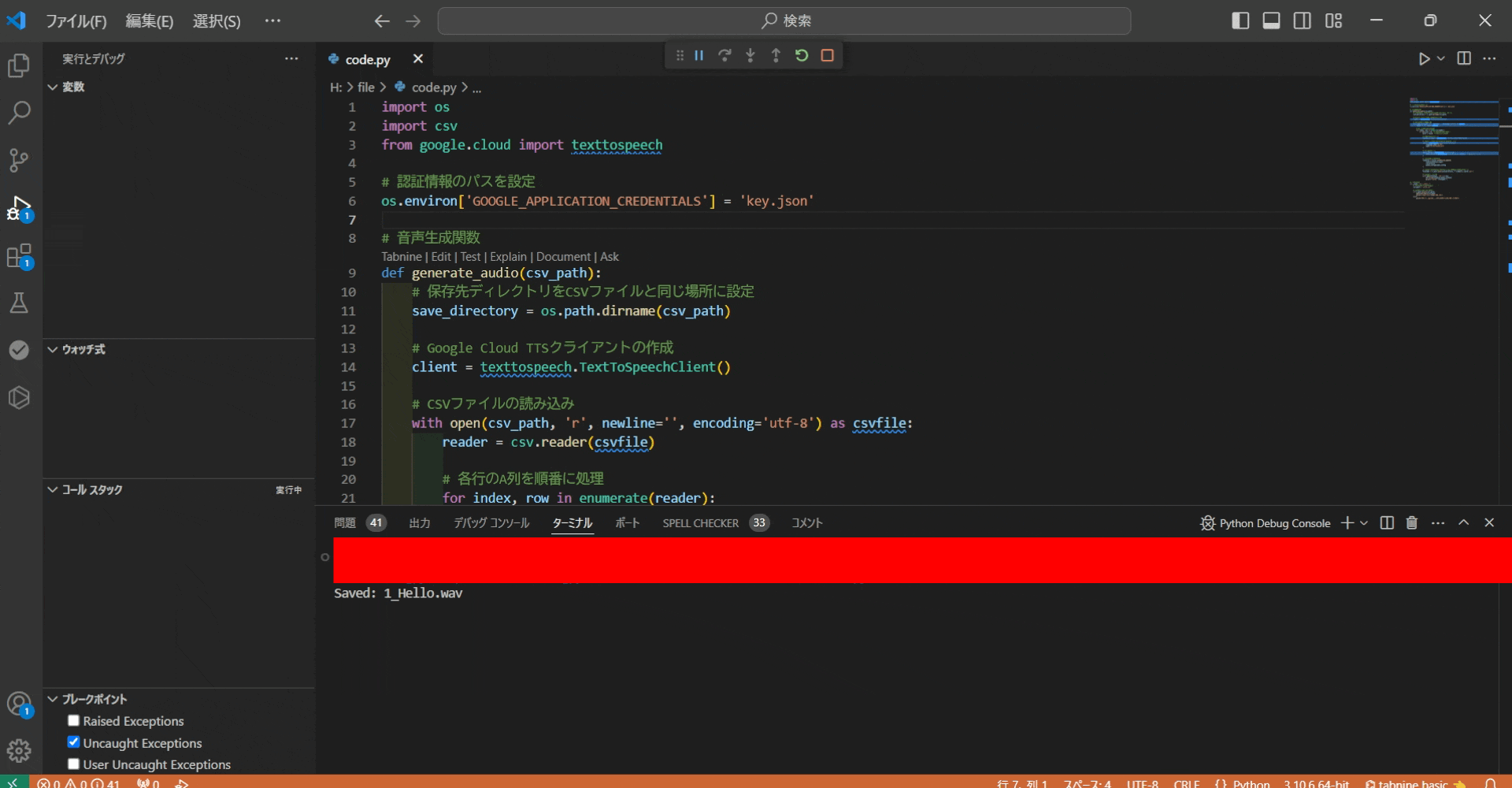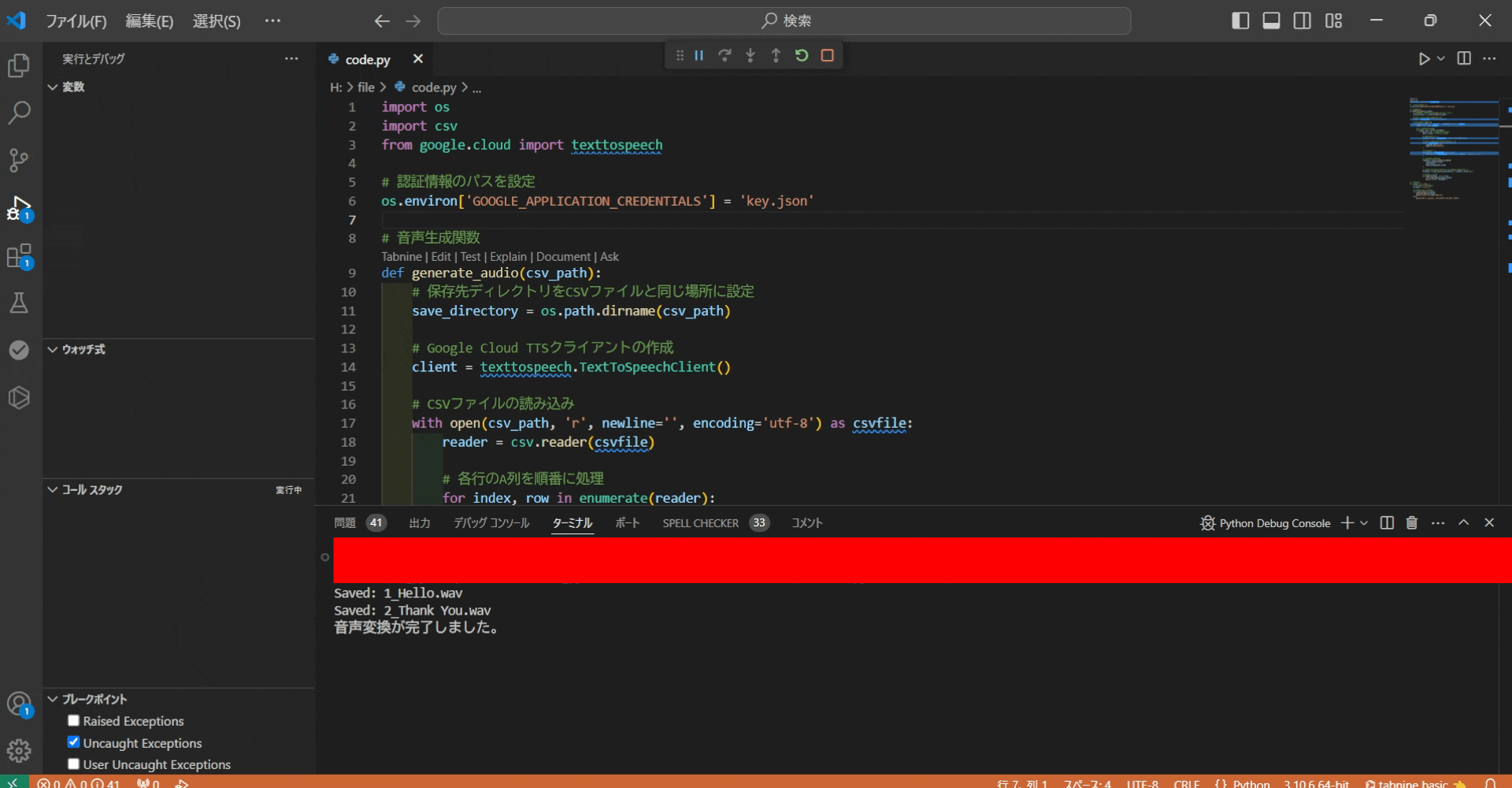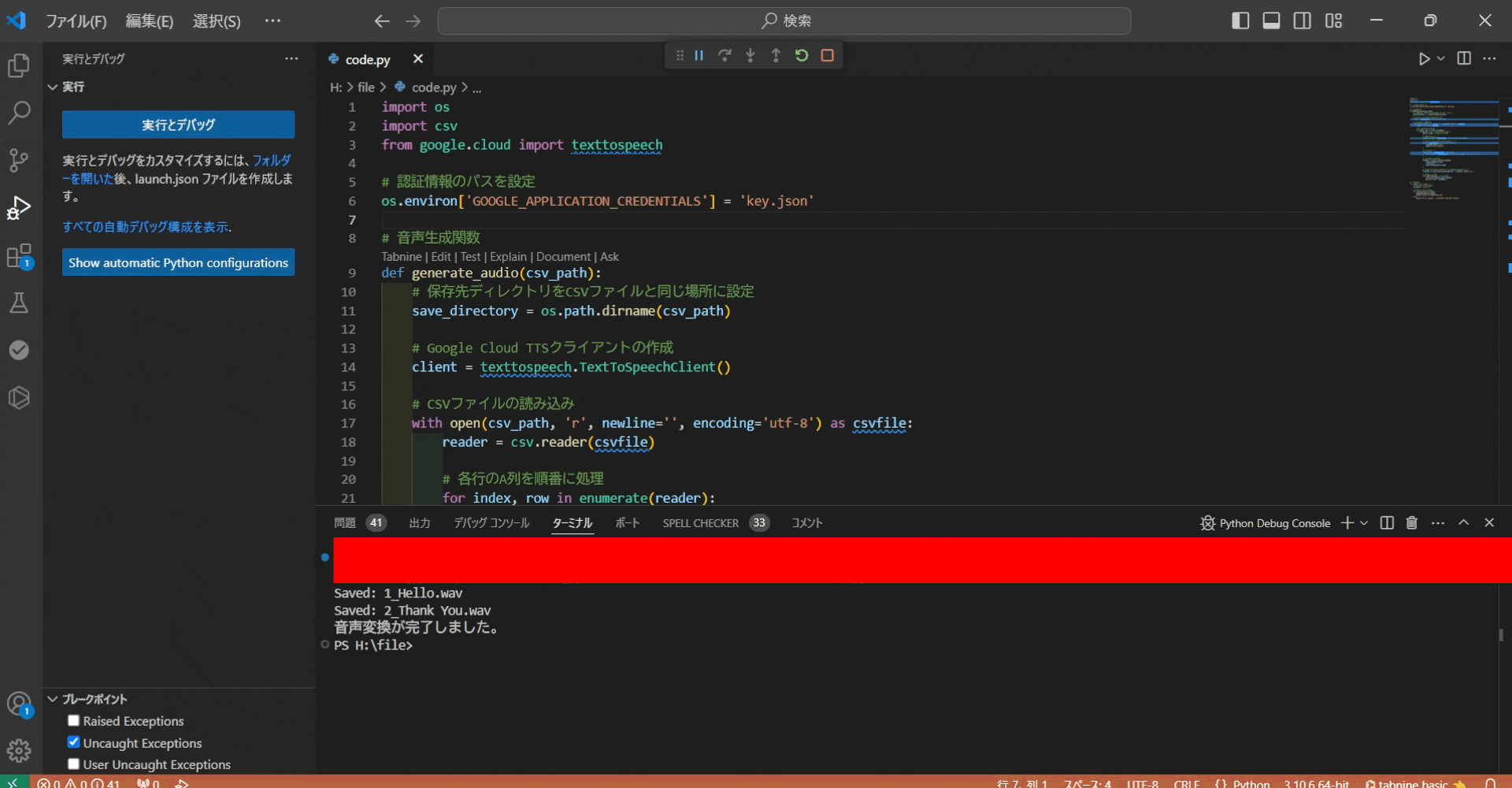
スクリプトを実行すると、csv(voice.csv)にのA列にあるテキストを読み込み、
wav形式で保存します。
wavファイルの保存先は、実行したPythonのコードと同じ断層です。
まとめ
Google Text-to-Speechは、テキストを簡単に音声に変換する強力なツールです。
特にPythonと組み合わせることで、柔軟に自動音声生成を行うことが可能になります。
本記事では、APIの取得からPythonによる実装までを詳細に解説しました。
業務の効率化や教育コンテンツの作成など、さまざまな用途で活用してみてください。
Google Text-to-Speechを使うことで、ナレーション、案内、教育用途、さらには商用プロジェクトでの音声合成など、多彩なシーンで活用することができます。
また、Pythonのコードを使えば、複数のテキストを自動的に音声ファイルに変換するプロセスを効率化でき、生産性を向上させることができます。
APIの設定や実装手順は一見複雑に思えますが、
本記事を参考にすれば初めての方でも問題なく取り組むことができるでしょう。
Google Cloudの無料枠を上手に利用し、まずは個人プロジェクトから始めてみるのも良いでしょう。音声合成の楽しさと可能性をぜひ体験してみてください。

