

- PDFファイルを結合する。
- PDFを1ページずつ分割する。
Pythonを使えば、複数のPDFファイルを1つに結合とPDFファイルを1つずつ分割することが簡単にできます。
本記事では、PyPDF2ライブラリを使用してPDFを分割や結合などの操作を実行する方法を詳しく解説します。
- PythonでPDFを操作したい。
- 紙の書類をデジタル化し、管理したい
- 多数のPDFファイルを扱いたい人
- 学術論文や研究資料を整理する学生や研究者
- PDFを利用したドキュメント管理を効率化したいエンジニア
PyPDF2の機能と使う場面
PyPDF2は、PythonでPDFファイルを操作するためのライブラリです。
- PDFの結合と分割: 複数のPDFファイルを一つにまとめる、PDFファイルをページ単位で分割。
- ページの抽出と追加: 特定のページを抽出、新しいページの追加。
- メタデータの操作: PDFのメタデータ(タイトル、著者、作成日など)の読み取り、変更。
PDFの結合
import PyPDF2
# PDFファイルを読み込む
pdf1 = open('document1.pdf', 'rb')
pdf2 = open('document2.pdf', 'rb')
# PdfMergerオブジェクトを作成
merger = PyPDF2.PdfMerger()
# PDFファイルを追加
merger.append(pdf1)
merger.append(pdf2)
# 結合されたPDFをファイルとして書き出し
with open('new_document.pdf', 'wb') as output:
merger.write(output)
# リソースを解放
pdf1.close()
pdf2.close()
merger.close()PDFファイルをページ単位で分割
import PyPDF2
# 分割するPDFファイルを開く
input_pdf = open('document.pdf', 'rb')
# PdfReaderオブジェクトを作成
reader = PyPDF2.PdfReader(input_pdf)
# 分割されたページを新しいPDFファイルとして保存
for i in range(len(reader.pages)):
writer = PyPDF2.PdfWriter()
writer.add_page(reader.pages[i])
with open(f'page_{i+1}.pdf', 'wb') as output_pdf:
writer.write(output_pdf)
# リソースを解放
input_pdf.close()ページの抽出
import PyPDF2
# 抽出するPDFファイルを開く
input_pdf = open('document.pdf', 'rb')
# PdfReaderオブジェクトを作成
reader = PyPDF2.PdfReader(input_pdf)
# 抽出するページ(1ページ目)
page = reader.pages[0]
# 新しいPDFファイルに抽出したページを追加
writer = PyPDF2.PdfWriter()
writer.add_page(page)
# 抽出したページを保存
with open('extracted_page.pdf', 'wb') as output_pdf:
writer.write(output_pdf)
# リソースを解放
input_pdf.close()PDFのメタデータを読み取る
import PyPDF2
# PDFファイルを開く
input_pdf = open('document.pdf', 'rb')
# PdfReaderオブジェクトを作成
reader = PyPDF2.PdfReader(input_pdf)
# メタデータを取得
metadata = reader.metadata
# メタデータを表示
print(metadata)
# リソースを解放
input_pdf.close()
フォルダー内すべてのPDFを1つに結合
ユーザーが選択したフォルダー内のすべてのPDFファイルを結合し、1つのPDFファイルとして保存します。
Tkinterを使用してフォルダー選択ダイアログを表示し、選択されたフォルダー内のPDFファイルをPyPDF2のPdfMergerクラスで結合します。
ソースコード
import os
from PyPDF2 import PdfMerger
from tkinter import Tk, filedialog
# Tkinterを使用してフォルダー選択ダイアログを表示
root = Tk()
root.withdraw() # メインウィンドウを表示しないようにする
folder_path = filedialog.askdirectory()
if folder_path:
# フォルダー名を取得
folder_name = os.path.basename(folder_path)
# PdfMergerオブジェクトを作成
merger = PdfMerger()
# フォルダー内のすべてのPDFファイルを取得し、結合
for filename in os.listdir(folder_path):
if filename.endswith('.pdf'):
file_path = os.path.join(folder_path, filename)
merger.append(file_path)
# 結合されたPDFファイルの保存
output_path = os.path.join(folder_path, f'{folder_name}.pdf')
merger.write(output_path)
merger.close()
print(f"結合されたPDFファイルが{output_path}に保存されました。")
else:
print("フォルダーが選択されませんでした。")
UdemyでPythonを学習
Udemyは、オンデマンド式の学習講座です。
趣味から実務まで使えるおすすめの講座を紹介します。
- 現役シリコンバレーエンジニアが教えるPython 3 入門 + 応用 +アメリカのシリコンバレー流コードスタイル
Pythonをインストールから環境設定、基本文法が学習
さらに暗号化、インフラ自動化、非同期処理についても学べます。
Pythonを基礎から応用まで学びたい人におすすめ
- みんなのAI講座 ゼロからPythonで学ぶ人工知能と機械学習 【2024年最新版】
機械学習ライブラリで文字認識や株価分析などを行う。
人口知能やニューラルネットワーク、機械学習を学びたい人におすすめ。
- 【世界で55万人が受講】データサイエンティストを目指すあなたへ〜データサイエンス25時間ブートキャンプ〜
統計分析、機械学習の実装、ディープラーニングの実装を学習。
データサイエンティストになりたい人におすすめ。
- 0から始めるTkinterの使い方完全マスター講座〜Python×GUIの基礎・応用〜
TkinterのGUIを作成から発展的な操作までアプリ実例を示して学習。
アプリ開発したい人におすすめ。
解説
- モジュール名
「os」:ファイルパスの操作やフォルダーのリストを取得します。
「PyPDF2」:PDFファイルの読み取りおよび書き込みを行います。
「tkinter」:GUIを使用してフォルダー選択ダイアログを表示します。
PyPDFは、標準ライブラリではないので、インストール必要があります。
コマンドプロンプト(Windows)に入力して、実行します。
pip install PyPDF2- フィールド(メンバ変数)
「root」:Tkinterのメインウィンドウオブジェクト。GUIダイアログの親ウィンドウとして機能する。
「folder_path」:ユーザーが選択したフォルダーのパス。
「folder_name」:選択したフォルダーの名前。
「merger」:PDFファイルを結合するためのPdfMergerオブジェクト。
「output_path」:結合されたPDFファイルの保存先パス。
- それぞれのクラス(関数・メソッド)
PdfMergerクラス
PDFファイルを結合するためのオブジェクトを提供します。
ファイルを追加していき、最終的に1つのPDFファイルとして出力します。
Tkクラス
Tkinterのメインウィンドウオブジェクトを作成します。
GUIアプリケーションの基本ウィンドウとして機能します。
filedialog.askdirectoryメソッド
フォルダー選択ダイアログを表示し、
ユーザーが選択したフォルダーのパスを取得します。
os.path.basenameメソッド
指定されたパスからフォルダー名を取得します。
os.listdirメソッド
指定されたフォルダー内のファイルとサブフォルダーのリストを取得します。
merger.appendメソッド
指定されたPDFファイルを結合するために追加します。
merger.writeメソッド
結合されたPDFファイルを指定されたパスに保存します。
merger.closeメソッド
PdfMergerオブジェクトを閉じてリソースを解放します。
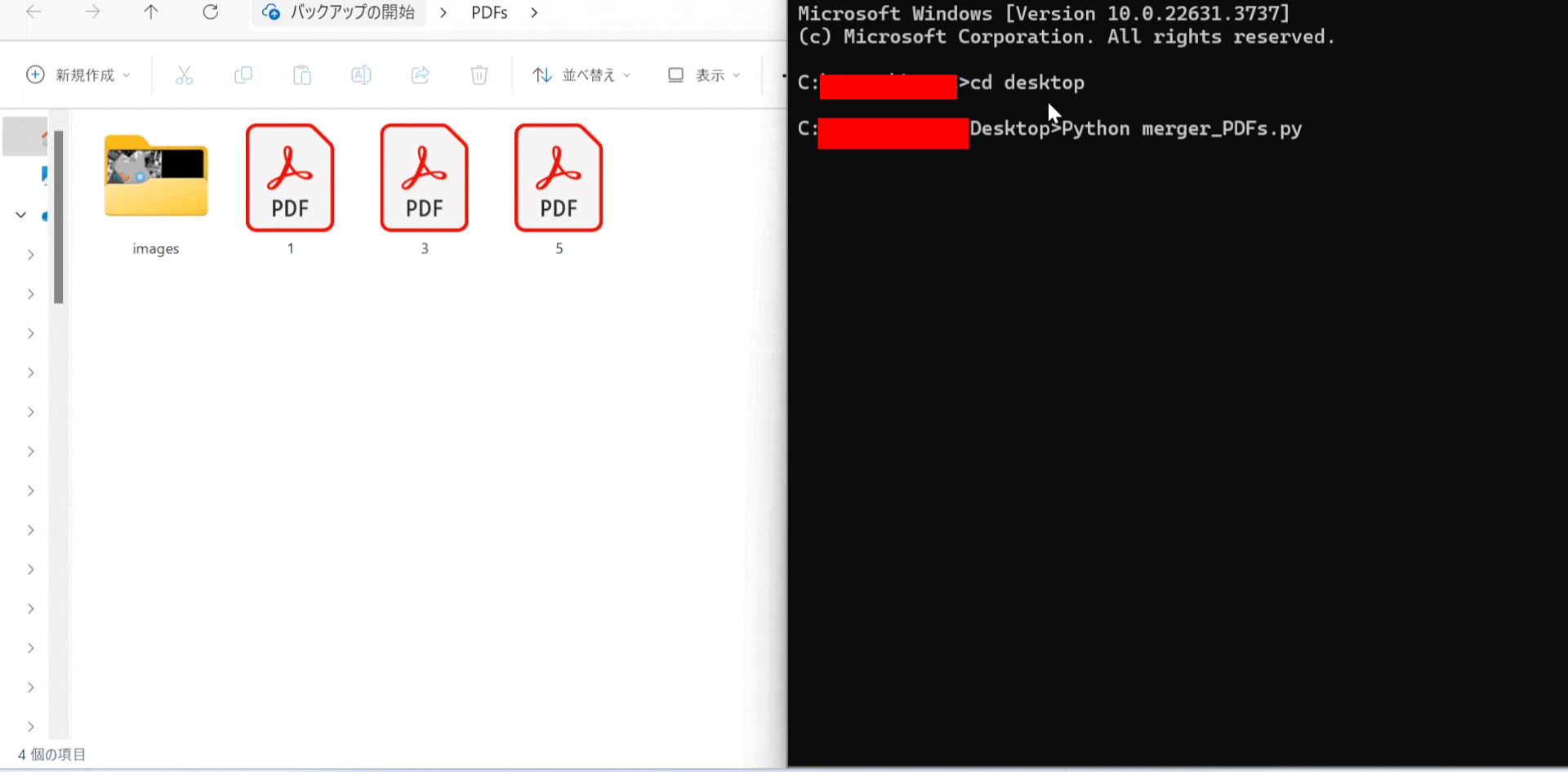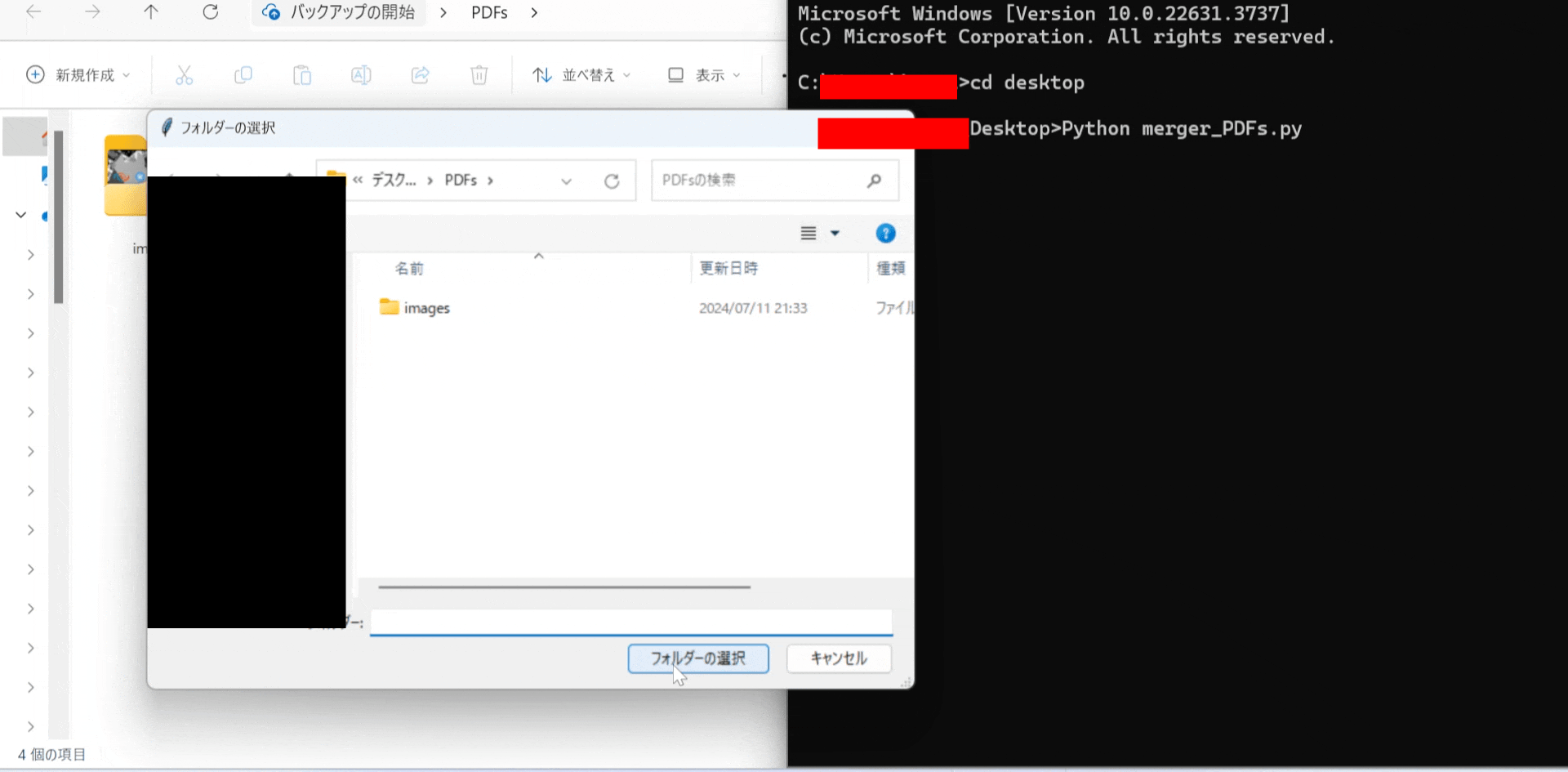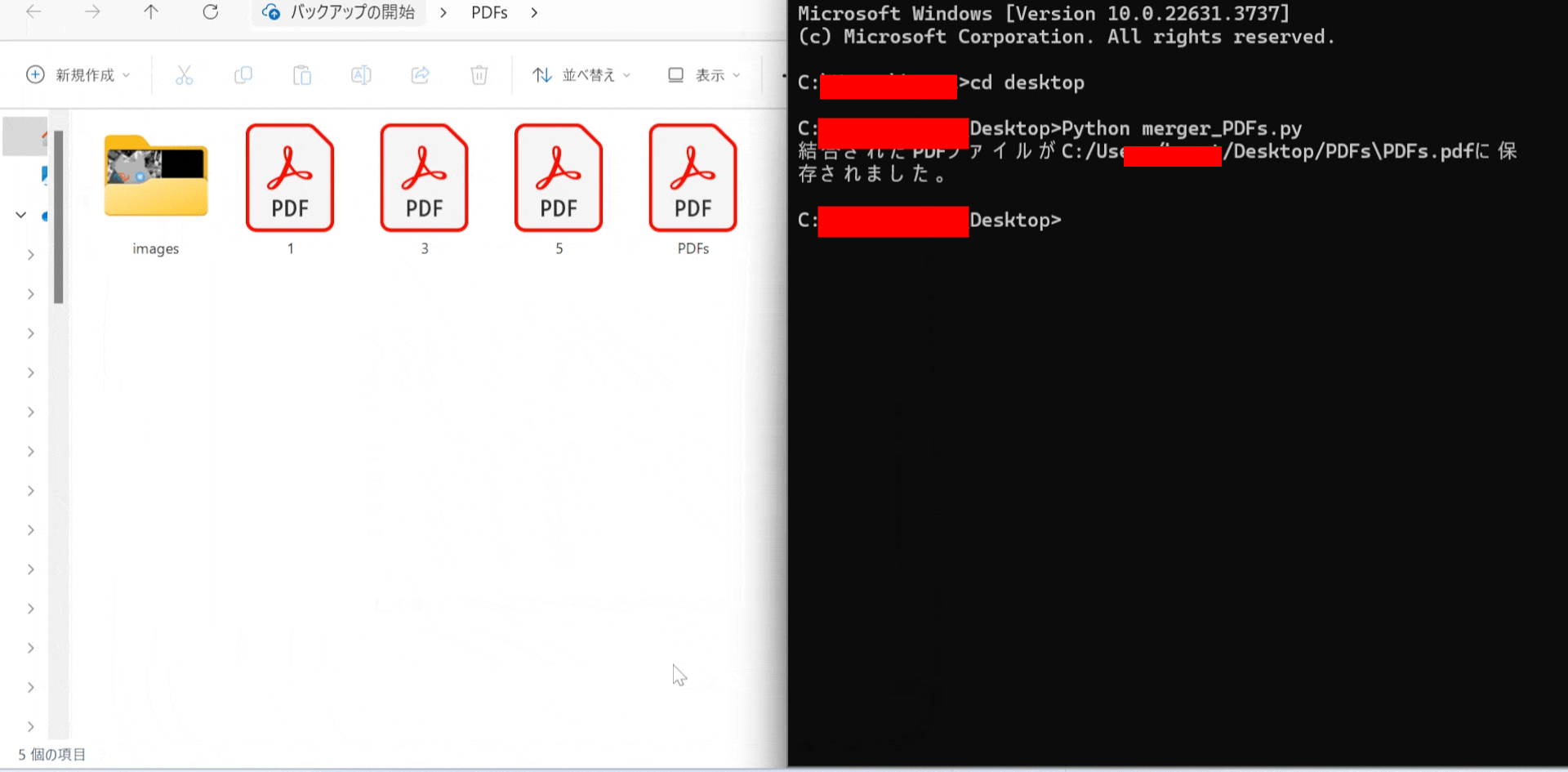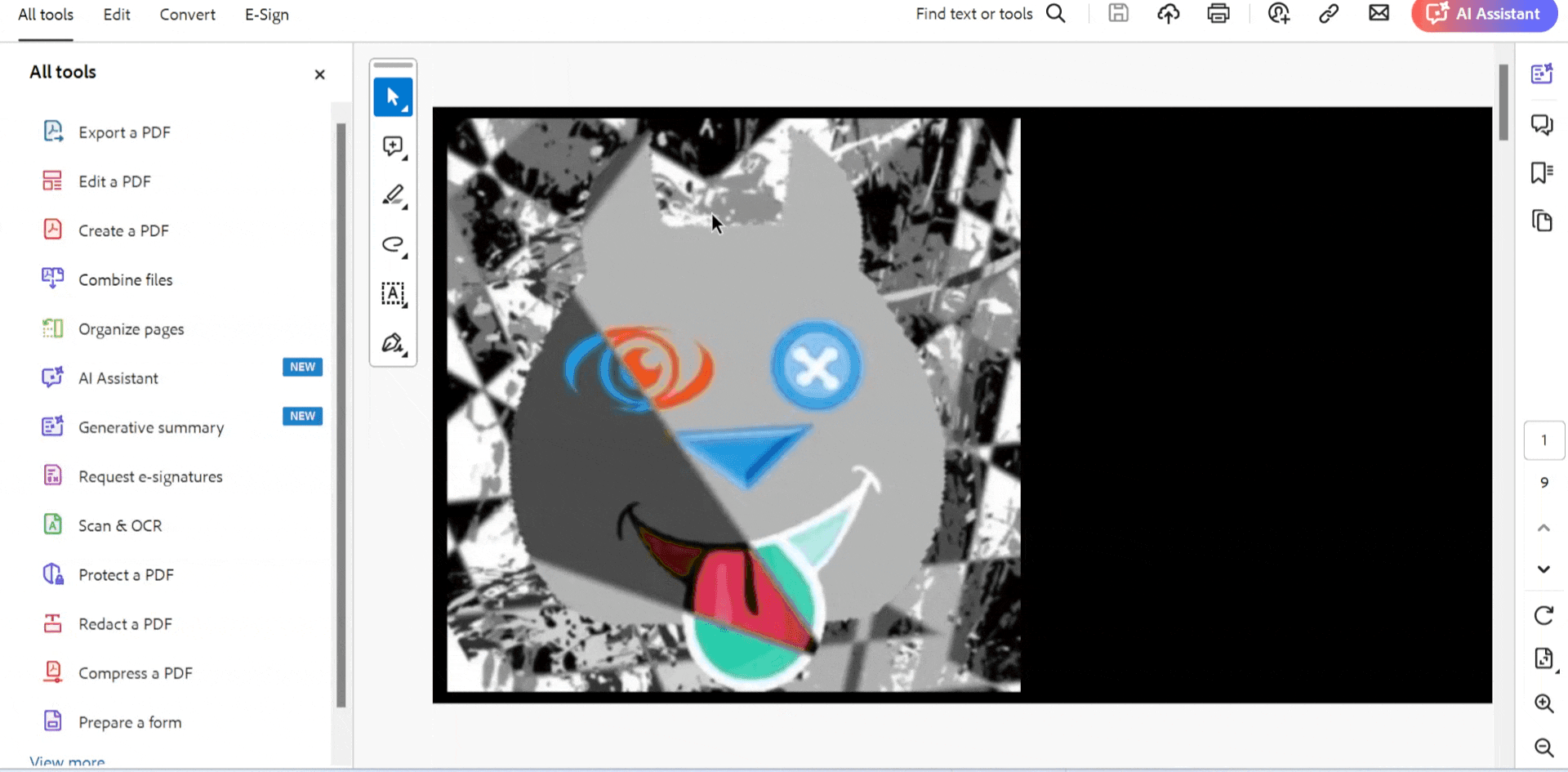
実演
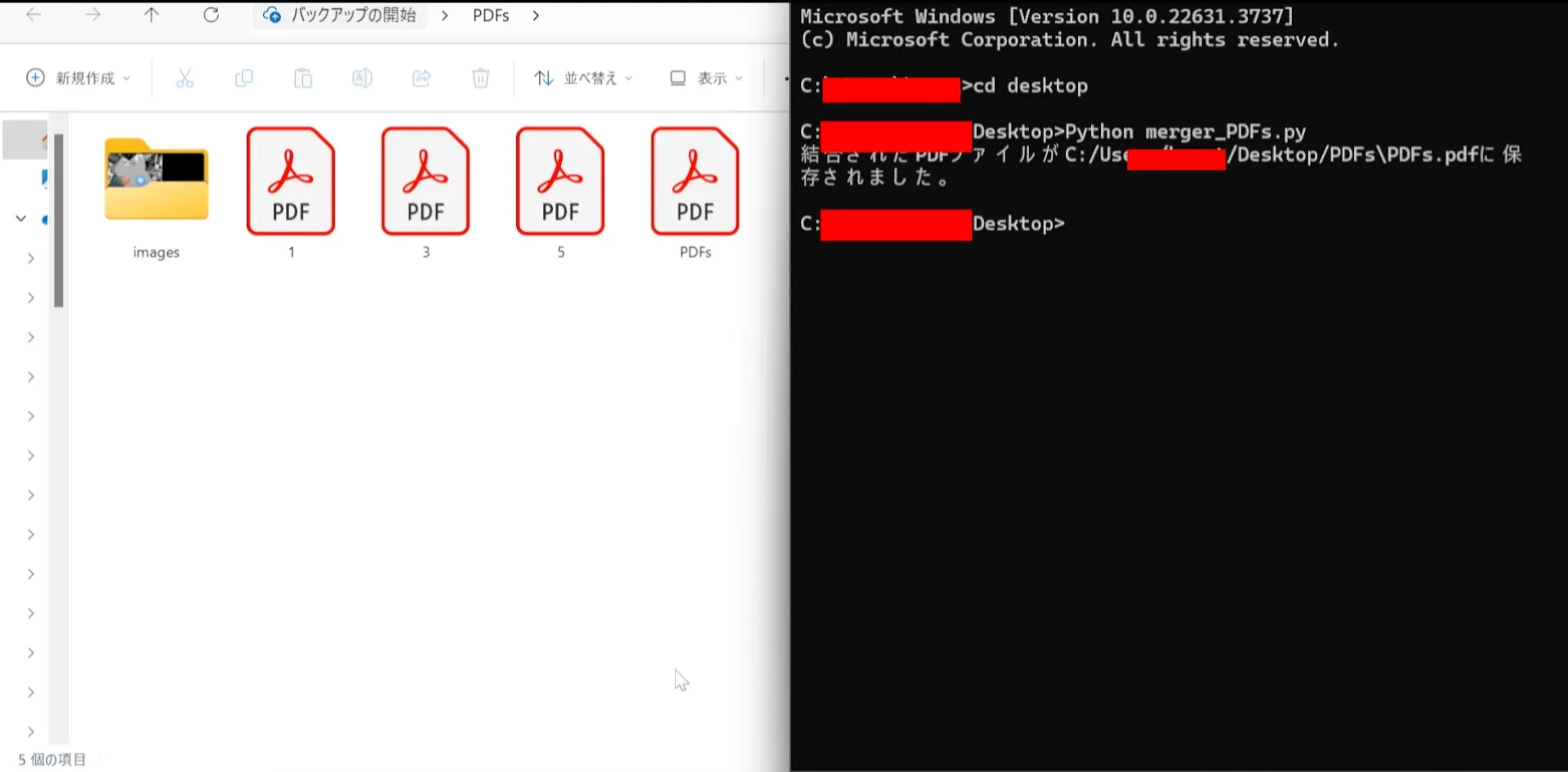
フォルダー選択ダイアログが表示されるので、結合したいPDFファイルが含まれているフォルダーを選択します。
選択されたフォルダー内のすべてのPDFファイルが結合され、新しいPDFファイルとして保存されます。
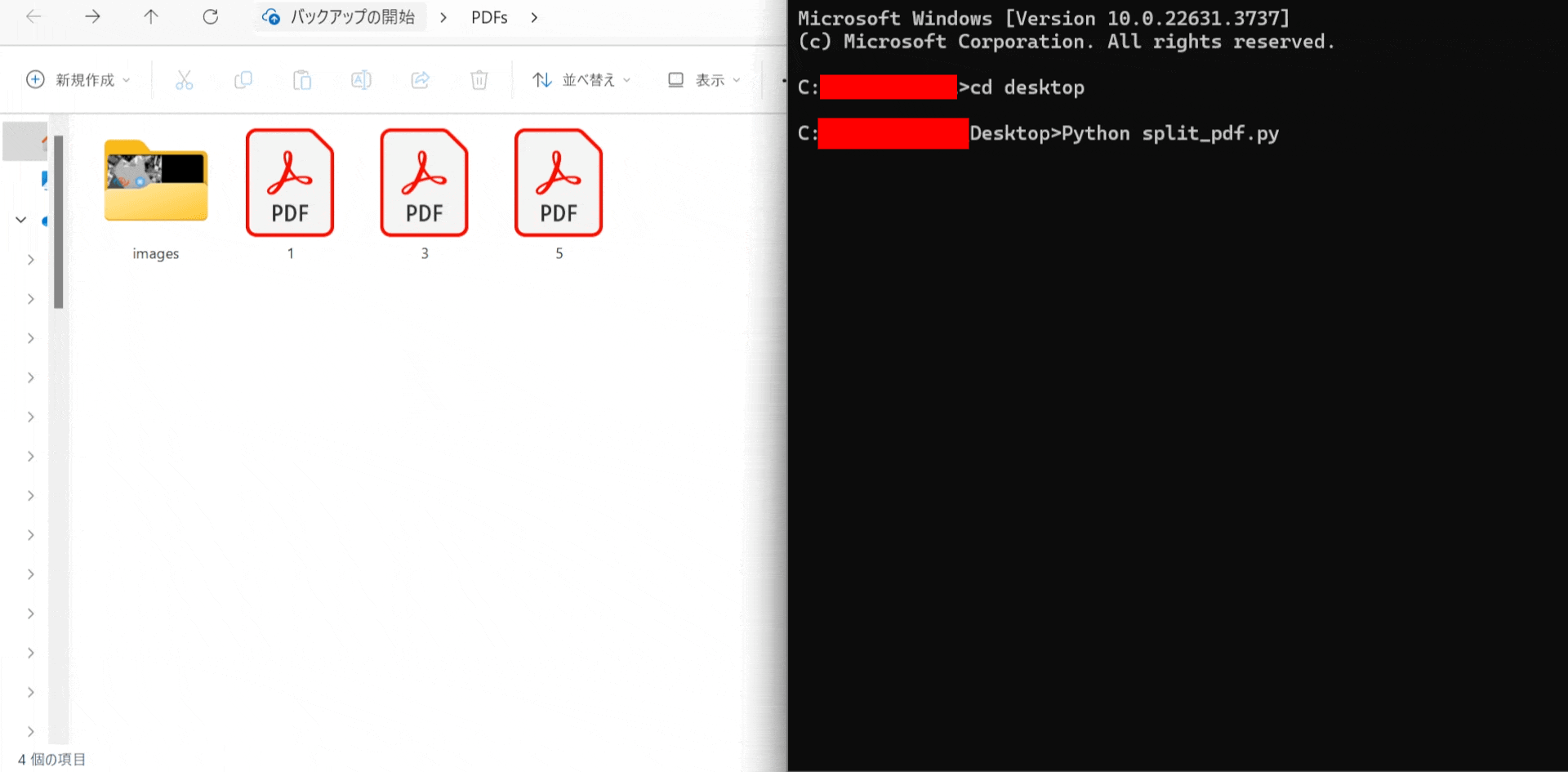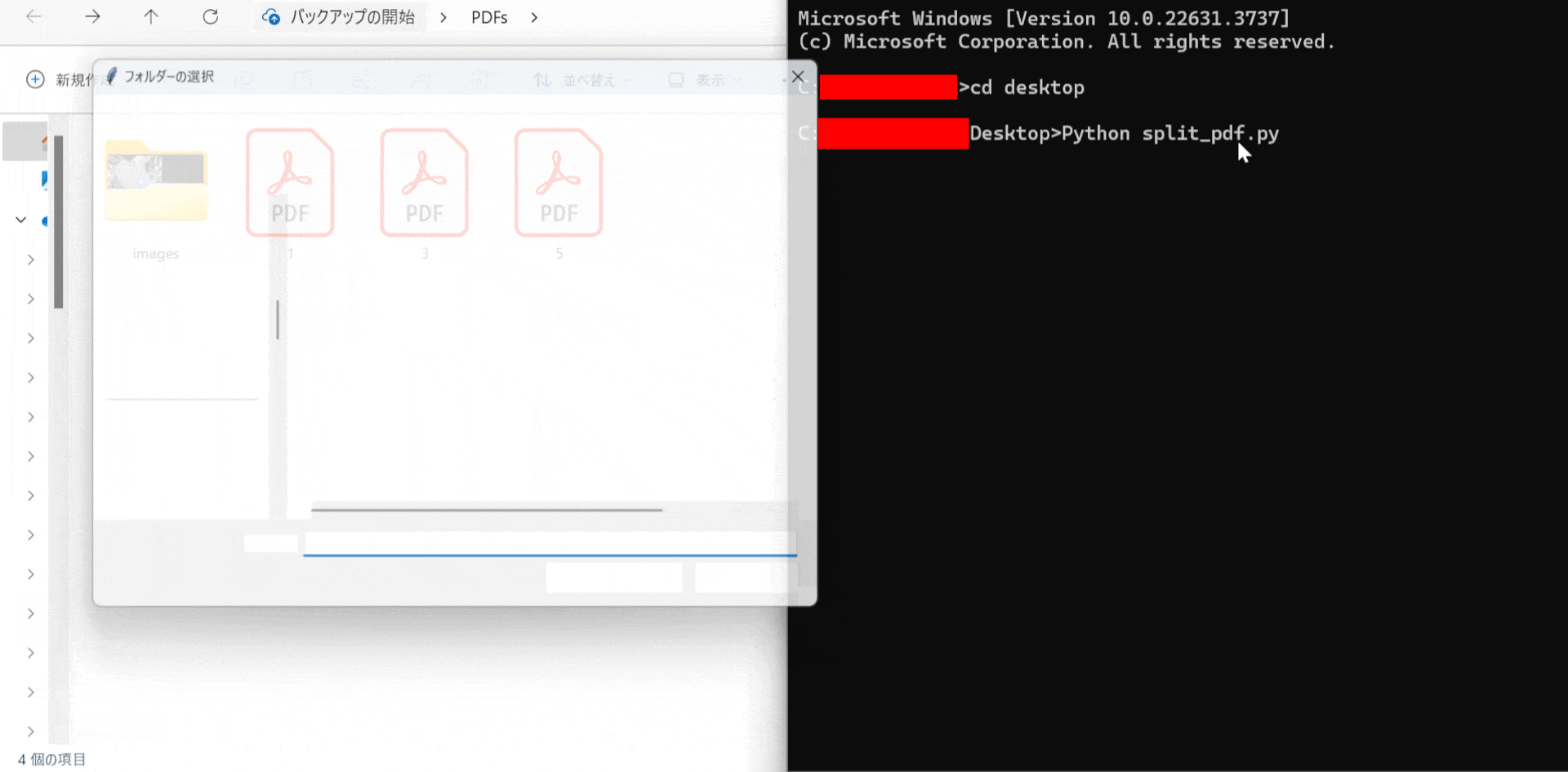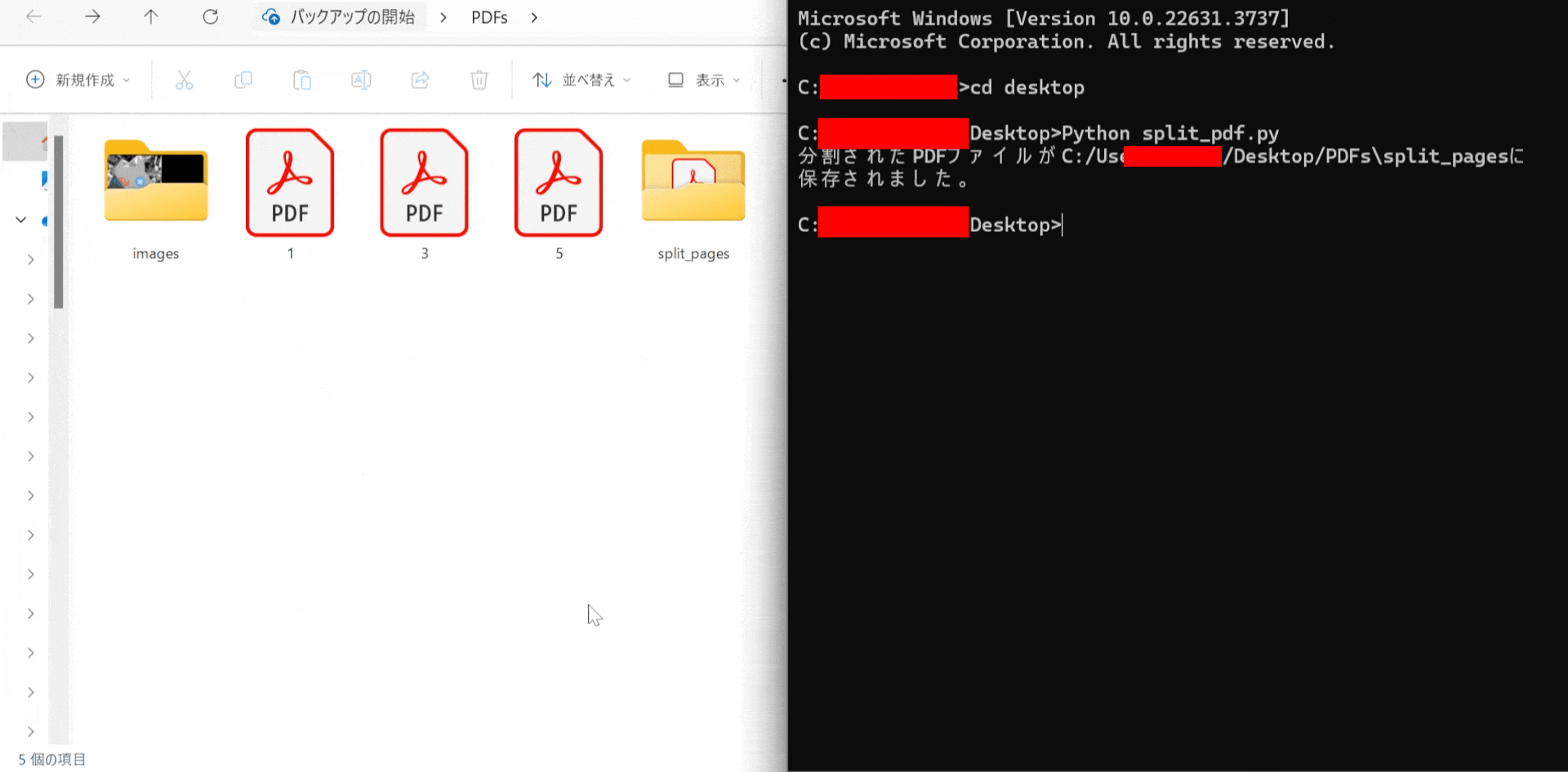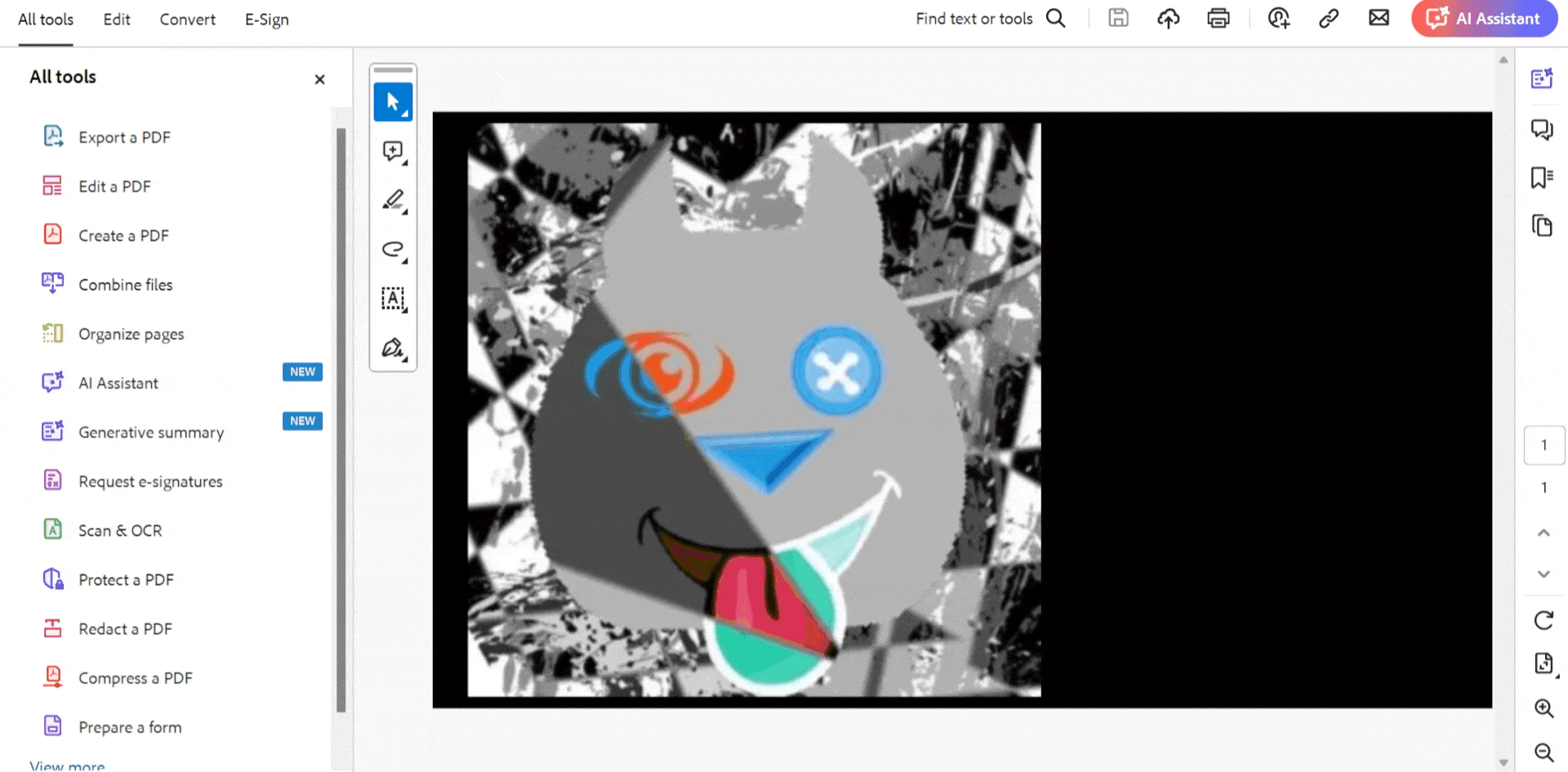
フォルダー内のPDFを1ページずつ分割
次にユーザーが選択したフォルダー内のすべてのPDFファイルを各ページごとに分割し、個別のPDFファイルとして保存します。
フォルダー内の各PDFファイルを読み込み、それぞれのページを新しいPDFファイルとして保存します。
ソースコード
import os
from PyPDF2 import PdfReader, PdfWriter
from tkinter import Tk, filedialog
# Tkinterを使用してフォルダー選択ダイアログを表示
root = Tk()
root.withdraw() # メインウィンドウを表示しないようにする
folder_path = filedialog.askdirectory()
if folder_path:
# 出力用のフォルダーを作成
output_folder = os.path.join(folder_path, 'split_pages')
os.makedirs(output_folder, exist_ok=True)
# フォルダー内のすべてのPDFファイルを処理
for filename in os.listdir(folder_path):
if filename.endswith('.pdf'):
file_path = os.path.join(folder_path, filename)
pdf = PdfReader(file_path)
# 各ページを個別のPDFファイルとして保存
for page_num in range(len(pdf.pages)):
pdf_writer = PdfWriter()
pdf_writer.add_page(pdf.pages[page_num])
# 新しいPDFファイル名を作成
output_filename = os.path.join(output_folder, f'{os.path.splitext(filename)[0]}_page_{page_num + 1}.pdf')
with open(output_filename, 'wb') as output_pdf:
pdf_writer.write(output_pdf)
print(f"分割されたPDFファイルが{output_folder}に保存されました。")
else:
print("フォルダーが選択されませんでした。")
解説
上記と同じモジュールとフィールドは省略します。
- フィールド(メンバ変数)
「filename」:現在処理中のPDFファイルの名前。
「file_path」:現在処理中のPDFファイルのフルパス。
「pdf」:現在読み込まれているPDFファイルのPdfReaderオブジェクト。
「page_num」:現在処理中のページ番号。
「pdf_writer」:新しいPDFファイルを作成するためのPdfWriterオブジェクト。
「output_filename」:分割された各ページのPDFファイル名。
- それぞれのクラス(関数・メソッド)
PdfReaderクラス
PDFファイルを読み取るためのオブジェクトを提供します。
PDFファイルを開いてページごとの情報にアクセスできます。
PdfWriterクラス
PDFファイルを作成するためのオブジェクトを提供します。
ページを追加して新しいPDFファイルとして保存します。
os.path.joinメソッド
複数のパスコンポーネントを結合して1つのパスを作成します。
os.makedirsメソッド
指定されたパスにディレクトリを作成します。
exist_ok=Trueオプションを指定することで、すでに存在する場合でもエラーを発生させません。
os.listdirメソッド
指定されたフォルダー内のファイルとサブフォルダーのリストを取得します。
pdf_writer.add_pageメソッド
PdfWriterオブジェクトにページを追加します。
pdf_writer.writeメソッド
PdfWriterオブジェクトの内容を指定されたファイルに書き込みます。
os.path.splitextメソッド
ファイル名と拡張子を分割します。
実演
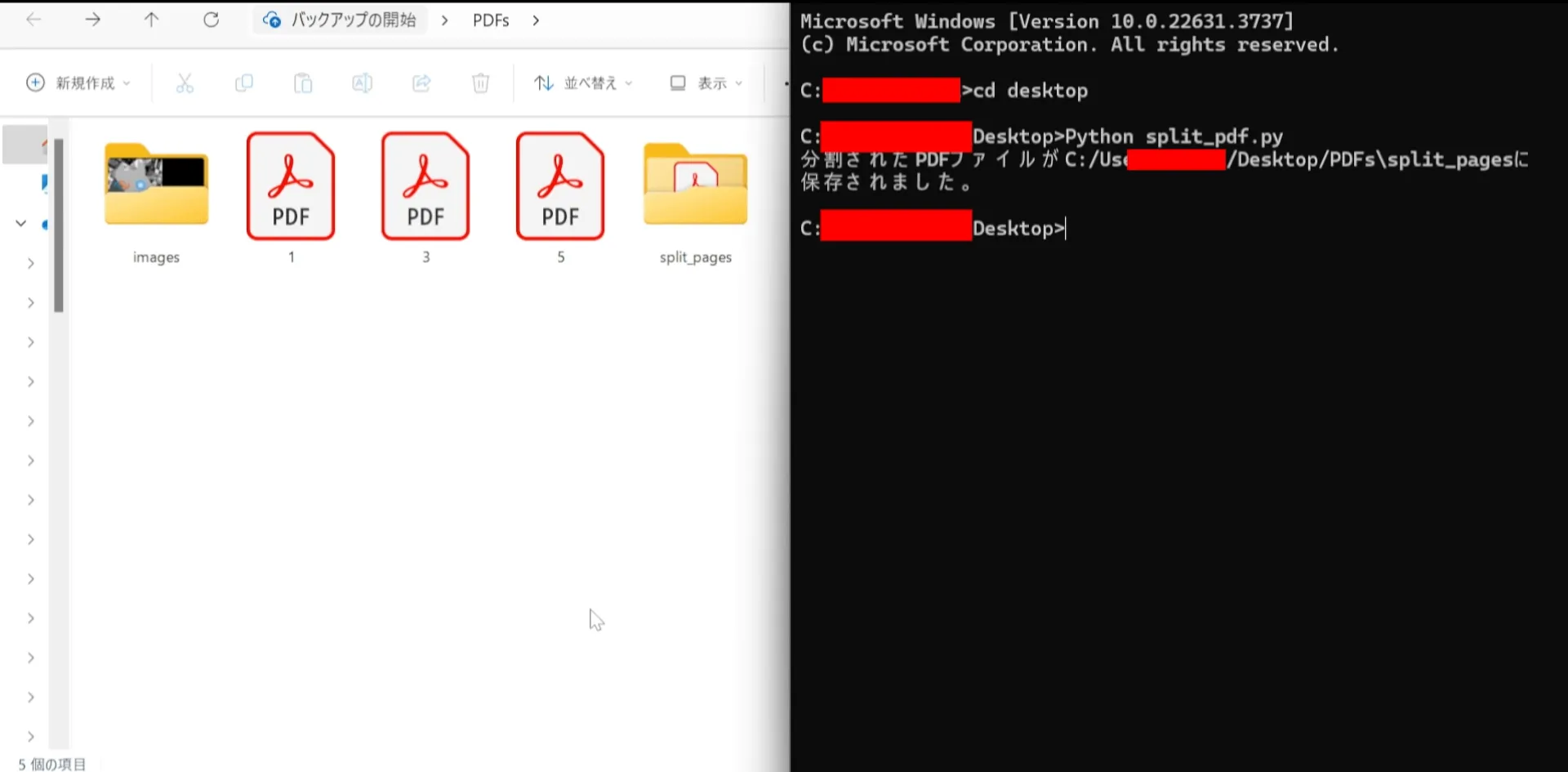
フォルダー選択ダイアログが表示されるので、分割したいPDFファイルが含まれているフォルダーを選択します。
選択されたフォルダー内のすべてのPDFファイルがページごとに分割され、新しいPDFファイルとして保存されます。
まとめ
この記事では、Pythonを使ってPDFファイルを結合および分割する方法を紹介しました。
PyPDF2ライブラリを使用することで、これらの操作を簡単に実行できます。
業務効率化や資料管理の向上に有効となります。

